用 AI Agent 处理复杂流程:先写 Workflow,再写 Prompt
Posted on Fri 06 February 2026 in Journal
| Abstract | 用 AI Agent 处理复杂流程:先写 Workflow,再写 Prompt |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Status | v1.0 |
| Updated | 2026-02-06 |
| License | CC-BY-NC-ND 4.0 |
短大纲(给忙人)
展开看看
- **先把问题说清楚**:复杂流程的"复杂"不是步骤多,而是不确定性多(输入乱、分支多、工具杂、回滚难) - **Super Agent 做三件事**:识别任务 → 分派任务 → 汇总成果(别亲自下场写每一步) - **Sub Agent 遵循 SRP**:一个 SubAgent 只对一种能力负责,输入/输出可测试、可替换 - **SOLID 全家桶**:SRP 只是开头,OCP/LSP/ISP/DIP 在 Agent 系统里一样管用 - **A2A 通讯用结构化数据**:别靠自然语言"意会",要有 schema、版本、错误码、可追踪 id - **Prompt 要做版本管理**:别塞数据库,直接用目录 + Git;可 diff、可 review、可回滚 - **Workflow:先设计,再执行**:把流程当"程序"写出来(DAG/状态机/重试策略),然后让 Agent 去跑 - **MCP:把工具接入标准化**:SubAgent 通过 MCP 用工具,Super Agent 只管调度与权限边界 - **LangGraph 实战 Demo**:用 Supervisor + SubAgent 模式实现一个临床论文写作 Workflow开头先扎心:你不是缺 Prompt,你是缺"流程的骨架"
我见过很多团队上来就"加 Prompt"。流程越复杂,Prompt 越长,最后像一锅粥:谁都能往里加一勺酱油,但没人知道锅里到底是什么味儿。
你想用 AI Agent 处理一个复杂流程,比如:
- 新需求来了:要查历史文档、看代码、跑测试、写变更说明、发通知、顺手再写个 FAQ
- 安全审计来了:要拉取日志、关联工单、抽取证据、生成报告,还要对"不可披露信息"做脱敏
- 或者更日常的:写一篇文章,图要渲染、引用要校验、素材要归档、还得保持风格不油腻
这些事不难在"步骤",难在"意外":
- 输入不干净:同一个字段有人叫
repo有人叫repository,还夹着半截中文 - 分支很多:失败后怎么办?要不要重试?重试要不要换策略?
- 工具一堆:本地脚本、API、MCP server、数据库、Git、CI......每个都有自己的脾气
- 结果要可审计:出了问题你得能回答"为什么是这个结论""哪一步用的什么依据"
所以我现在更倾向一句话:先写 Workflow,再写 Prompt。
1) 先把角色分清:Super Agent 与 SubAgent,不是"大模型分身术"
"Super Agent / SubAgent" 这个分法,很多人觉得只是换了个名字。其实不是——它的核心目的是把复杂度关进笼子里。
Super Agent:像项目经理,但更像"编排器"
Super Agent 的核心职责很简单,三件事:
- 识别与拆分任务:把"做一件大事"拆成"可交付的小事"
- 分派与编排执行顺序(workflow):谁先谁后、并行还是串行、失败怎么兜底
- 汇总与验收成果:把 SubAgent 的输出拼成可交付物,并做一致性检查
它最重要的能力不是"写得好",而是"管得住"。
SubAgent:SRP(单一职责)不是口号,是救命
SubAgent 我建议强行遵循 SRP:一个 SubAgent 只负责一个领域能力。例如:
ResearchAgent:只负责检索与引用(输出来源、摘要、置信度)CodeAgent:只负责改代码/跑命令(输出 diff、测试结果)DocAgent:只负责把结构化输入写成文档(输出 markdown + 章节结构)DiagramAgent:只负责把 diagram code block 渲染成图片(输出路径 + 校验)
好处很现实:
- 可替换:某个 SubAgent 拉胯就换模型/换实现,不影响整个系统
- 可测试:给定输入,输出是否符合 schema?能不能做 golden test?
- 可控权限:需要网络的、能写文件的、能访问敏感数据的,权限边界更清晰
不只是 SRP:SOLID 五原则在 Agent 系统里全能用
SRP 只是开胃菜。写过后端服务的人对 SOLID 不会陌生——好消息是,这五条原则搬到 AI Agent 系统里几乎可以直接用。
OCP(开闭原则):加能力 = 加文件/加节点,不改已有代码
要新增一个工具(比如从 PubMed 扩展到 ClinicalTrials.gov),挂一个新 MCP Server 就行,SubAgent 代码不用动。要更新某个 Agent 的 prompt,改文件、发 PR,其他 Agent 完全无感。要加一个新 SubAgent,在 StateGraph 上加一个节点,已有节点不用碰。
LSP(里氏替换原则):遵守契约的 Agent 可以随时互换
只要新的 SubAgent 遵守同一套 A2A schema(输入/输出格式一致),就能无感替换。比如把 literature_agent 底层从 GPT-4o-mini 换成 Claude,Supervisor 完全不需要知道——它只关心"给你 topic,你还我 references 列表"。
ISP(接口隔离原则):给 Agent 最小够用的工具集
writer_agent 只有写作工具,不给它搜索工具——它不需要、也不应该自己去搜索。如果你把所有 tools 都塞给一个 Agent,它就容易"跑偏":本来该写论文的,看到有搜索工具就自己去搜了一轮,产出不可预期。
DIP(依赖倒置原则):依赖抽象(契约),不依赖具体实现
Supervisor 不依赖"literature_agent 是用 GPT-4o 跑的"这个细节,它只依赖 A2A 消息契约。SubAgent 不依赖"工具是直接调 API 还是走 MCP",它只依赖 @tool 接口。Workflow 不依赖"用 LangGraph 还是 Temporal",它只依赖 DAG 定义。
速查表放在这里,方便你对照检查自己的 Agent 系统:
| 原则 | Agent 系统中的含义 | 反面教材 |
|---|---|---|
| SRP | 一个 SubAgent 只负责一个领域能力 | 一个 Agent 又搜索又写作又审稿 |
| OCP | 加新能力 = 加文件/加节点 | 每次加功能都要改 Supervisor 的 prompt |
| LSP | 遵守 A2A 契约即可互换 | 换个模型就要改调用方代码 |
| ISP | 每个 Agent 只拿自己需要的 tools | 所有 tools 全塞给每个 Agent |
| DIP | Agent 之间依赖契约,不依赖实现 | Supervisor 里硬编码 SubAgent 的模型名 |
2) A2A(Agent-to-Agent)通讯:别靠"自然语言默契",要靠契约
先对齐一下术语:A2A 在不同团队里含义不完全一样。Google 2025 年发布了一个 Agent2Agent Protocol 开放协议,专门解决跨平台 Agent 互操作的问题。我这篇文章里说的 A2A 更宽泛,泛指"Agent 与 Agent 之间的消息交互"——不管你用 Google 的协议、自研的 schema,还是 LangGraph 的 MessagesState,核心诉求是一样的:让 Agent 之间的沟通有契约、可追踪、能重试。
如果你让 SubAgent 用自然语言随便回一句"我做完了",Super Agent 很快会陷入两种尴尬:
- 要么不敢用:因为不知道这个结果靠不靠谱、缺不缺字段
- 要么瞎用:因为不知道错误在哪、重试该怎么做
解决办法很工程化:结构化消息 + schema + 版本。
一个能落地的 A2A 消息模板(JSON)
下面这个模板我自己很常用,你可以按需删减,但别丢掉关键字段(id/correlation_id/status/artifact/error)。
{
"protocol": "a2a.v1",
"id": "msg_20260206_000123",
"correlation_id": "run_20260206_210000",
"sender": "SuperAgent",
"receiver": "ResearchAgent",
"intent": "collect_references",
"input": {
"topic": "ai agent workflow",
"constraints": {
"language": "zh-CN",
"no_bare_url": true
}
},
"status": "ok",
"output": {
"references": [
{
"title": "Model Context Protocol - Specification",
"url": "https://modelcontextprotocol.io/specification/latest",
"notes": "MCP 规范入口,包含 lifecycle、tools、resources、prompts 等"
}
]
},
"artifact": [
{ "type": "markdown", "path": "content/journal/xxx.md" }
],
"error": null,
"metrics": { "latency_ms": 812, "tokens_in": 1200, "tokens_out": 350 }
}
你会发现它很"无聊"。但工程上,无聊就是稳定。
A2A 的两个关键习惯
- 强制输出 schema:哪怕 SubAgent 内部写得再自由,最终对外输出必须过 schema 校验
- 对失败分类:比如
VALIDATION_ERROR(输入不合规)、TOOL_ERROR(工具失败)、TIMEOUT(超时),不同错误的重试策略不一样
3) Prompt 版本管理:别用数据库,用目录 + 文件 + Git
有人喜欢把 prompt 存数据库,方便后台管理系统在线编辑。我的看法相反——直接用目录 + 文件 + Git。原因很朴素:
- 可 diff:这句改了什么,一眼就能看到
- 可 review:PR 上看 Prompt 变更,比在后台管理系统点点点靠谱
- 可回滚:线上出事,
git revert可能比你"回忆昨晚改了啥"更快
一个我觉得舒服的目录结构如下:
prompts/
super/
router.v1.md
evaluator.v1.md
agents/
research/
system.v1.md
user_template.v1.md
coder/
system.v1.md
user_template.v1.md
writer/
system.v1.md
outline.v1.md
draft.v1.md
schemas/
a2a/
message.v1.json
workflows/
blog_write.v1.yaml
audit_report.v1.yaml
再加一条"反直觉"的小建议:Prompt 的版本号不要追求语义化得太完美。 先做到"能回滚、能对比、能定位",比"v2.3.4"更重要。
4) Workflow:先设计(声明式),再执行(命令式)
"Agent 先写个程序:design workflow,再执行程序 execute workflow"——这个节奏,本质上就是工程界反复验证过的经典套路:
- Terraform:先写声明,再 apply
- CI Pipeline:先写 YAML,再 run
- Temporal / Airflow:先定义 DAG,再调度执行
Agent workflow 也一样:先把流程写成"能跑的结构",再让模型去跑。
一个最小可用的 workflow(DAG 思路)
比如写文章这件事,workflow 可以是:
collect_notes(收集要点)make_outline(生成大纲)draft(写正文)render_diagrams(渲染图)verify_links(检查链接)finalize(补 Summary、License、修改时间)
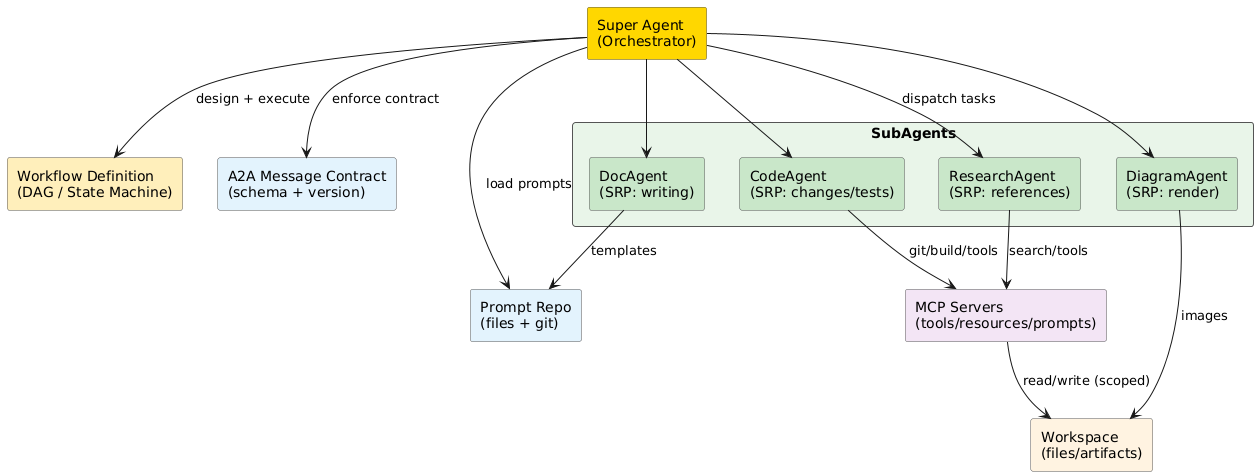
这里给一张结构图,帮助你把职责边界直观看清楚。
@startuml
skinparam componentStyle rectangle
skinparam shadowing false
skinparam rectangleBorderColor #555555
rectangle "Super Agent\n(Orchestrator)" as SA #FFD700
rectangle "Workflow Definition\n(DAG / State Machine)" as WF #FFEEBB
rectangle "SubAgents" as SUB #E8F5E9 {
rectangle "ResearchAgent\n(SRP: references)" as RA #C8E6C9
rectangle "CodeAgent\n(SRP: changes/tests)" as CA #C8E6C9
rectangle "DocAgent\n(SRP: writing)" as DA #C8E6C9
rectangle "DiagramAgent\n(SRP: render)" as GA #C8E6C9
}
rectangle "A2A Message Contract\n(schema + version)" as A2A #E3F2FD
rectangle "Prompt Repo\n(files + git)" as PR #E3F2FD
rectangle "MCP Servers\n(tools/resources/prompts)" as MCP #F3E5F5
rectangle "Workspace\n(files/artifacts)" as WS #FFF3E0
SA --> WF : design + execute
SA --> A2A : enforce contract
SA --> PR : load prompts
SA --> RA : dispatch tasks
SA --> CA
SA --> DA
SA --> GA
RA --> MCP : search/tools
CA --> MCP : git/build/tools
DA --> PR : templates
GA --> WS : images
MCP --> WS : read/write (scoped)
@enduml
执行层面的关键:重试策略要"写在流程里",别写在 Prompt 里
Prompt 里写"如果失败请重试三次",听起来很美,但它不可观测、也不可审计。 正确姿势是:把重试、超时、兜底策略写在 workflow 引擎里,让执行层负责。
5) MCP:把"工具接入"标准化,别让每个 Agent 都发明一遍轮子
MCP(Model Context Protocol)我更愿意把它看作:Agent 连接外部世界的"标准插口"。
没有 MCP 之前,每个 SubAgent 要用一个外部工具,你得自己写一套"连接 + 鉴权 + 参数序列化 + 错误处理"的胶水代码。5 个 Agent 用 5 个工具,就是 25 种组合,维护起来想哭。
有了 MCP 之后:
- SubAgent 需要工具,只管调
tool.xxx(),不关心底层怎么连、怎么鉴权 - Super Agent 不用关心"调用某个工具要不要先登录、token 放哪"
- 工具能力以 "MCP Server" 的形式独立部署:文件系统、数据库、PubMed、Git、CI、图渲染......想加就加,想换就换
MCP 协议本身很简洁,核心就三类能力:Tools(可调用的函数)、Resources(可读取的数据源)、Prompts(可复用的提示模板)。Agent 通过 JSON-RPC 和 MCP Server 通信,Server 端可以用任何语言实现——Python、TypeScript、Go、Rust 都有官方 SDK。
如果你已经有了一个能用的内部 API 或脚本,把它包装成 MCP Server 通常只需要几十行代码。后面第 8 节的 demo 里有一个具体的例子(mcp_pubmed_search),可以参考。
详细文档和参考实现我放在文末的扩展阅读里。
6) 把它们串起来:一段 A2A 序列,看看"复杂流程"怎么被管住
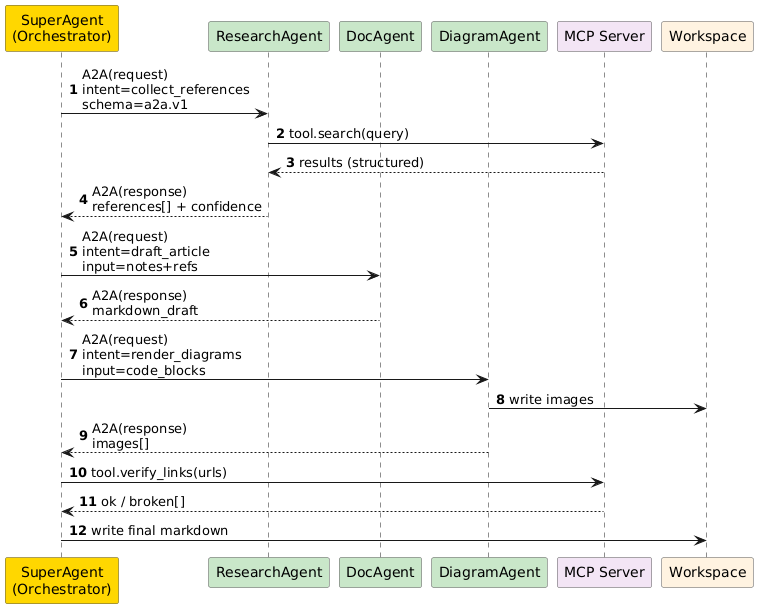
下面这张序列图不是为了好看,而是为了回答两个问题:
1) 每一步都能定位是谁产出的 2) 失败后怎么恢复(重试哪个节点,而不是整锅重来)
@startuml
autonumber
skinparam participantBackgroundColor #FAFAFA
skinparam participantBorderColor #555555
participant "SuperAgent\n(Orchestrator)" as SA #FFD700
participant "ResearchAgent" as RA #C8E6C9
participant "DocAgent" as DA #C8E6C9
participant "DiagramAgent" as GA #C8E6C9
participant "MCP Server" as MCP #F3E5F5
participant "Workspace" as WS #FFF3E0
SA -> RA : A2A(request)\nintent=collect_references\nschema=a2a.v1
RA -> MCP : tool.search(query)
MCP --> RA : results (structured)
RA --> SA : A2A(response)\nreferences[] + confidence
SA -> DA : A2A(request)\nintent=draft_article\ninput=notes+refs
DA --> SA : A2A(response)\nmarkdown_draft
SA -> GA : A2A(request)\nintent=render_diagrams\ninput=code_blocks
GA -> WS : write images
GA --> SA : A2A(response)\nimages[]
SA -> MCP : tool.verify_links(urls)
MCP --> SA : ok / broken[]
SA -> WS : write final markdown
@enduml
7) 一份"能抄就抄"的落地清单
你需要先做的 7 件事(按优先级)
- 定义 SubAgent 清单:每个 SubAgent 的 SRP 是什么?输入/输出是什么?
- 定义 A2A schema:至少包含
id、correlation_id、status、output、error - 把 Prompt 放进仓库:目录结构固定、命名统一、PR 审核机制
- 写 workflow 文件:DAG/状态机都行,关键是"可读、可追踪、可重跑"
- 接入 MCP 工具:先从最常用的 2-3 个开始(文件、搜索、Git/CI)
- 加上可观测性:每个节点的输入/输出摘要、耗时、失败原因(注意脱敏)
- 设计失败恢复:节点级重试、人工介入点、回滚策略(别全靠"再跑一次")
两个常见坑(我踩过的那种)
-
坑 1:SubAgent 职责漂移 今天让它"查资料",明天又让它"顺便写总结",最后它变成一个小号 Super Agent。
-
坑 2:把流程控制写进 Prompt Prompt 里越写越多"如果......则......否则......",最后你得到的是一个不可测试的"语言版状态机"。
8) 动手试一试:用 LangGraph 编排一篇临床医学论文
前面讲了一堆方法论,你可能已经有点痒了:说得好听,代码呢?
我女儿从事临床医学研究,她写论文时需要用到 AI Agent 来辅助她完成论文的写作。因此,我选择了临床医学论文写作作为示例,因为它天然就是"复杂流程"的标本——文献要从 PubMed 捞、统计分析不能瞎编、正文必须 IMRAD(Introduction-Methods-Results-And-Discussion)结构、最后还得过 CONSORT/STROBE 合规审查。少了哪一步,审稿人都会把你稿子打回来。
下面用 LangGraph 实现这个多 Agent 工作流,把前面的概念全用上:
- Super Agent -> LangGraph 的
supervisor节点(论文主编,决定下一步该谁干活) - SubAgent(SRP) ->
literature_agent、stats_agent、writer_agent、compliance_agent,各管各的 - A2A 结构化通讯 -> LangGraph 的
MessagesState(共享的、有类型的消息列表) - Workflow 先设计再执行 -> 整张
StateGraph就是声明式的 DAG,compile()之后才执行
先看一眼这个 workflow 的全貌
@startuml
skinparam shadowing false
skinparam activityBackgroundColor #f5f5f5
skinparam activityBorderColor #555555
(*) --> "==Supervisor==\n(论文主编)" #FFD700
"==Supervisor==\n(论文主编)" --> "LiteratureAgent\nPubMed 文献检索" #C8E6C9
"LiteratureAgent\nPubMed 文献检索" --> "==Supervisor==\n(论文主编)"
"==Supervisor==\n(论文主编)" --> "StatsAgent\n统计分析" #BBDEFB
"StatsAgent\n统计分析" --> "==Supervisor==\n(论文主编)"
"==Supervisor==\n(论文主编)" --> "WriterAgent\nIMRAD 撰写" #FFE0B2
"WriterAgent\nIMRAD 撰写" --> "==Supervisor==\n(论文主编)"
"==Supervisor==\n(论文主编)" --> "ComplianceAgent\nCONSORT 合规审查" #E1BEE7
"ComplianceAgent\nCONSORT 合规审查" --> "==Supervisor==\n(论文主编)"
"==Supervisor==\n(论文主编)" --> "END\n输出终稿" #F5F5F5
@enduml
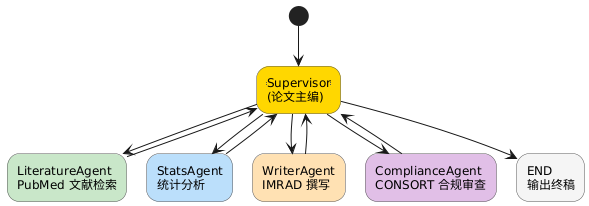
核心思路:Supervisor 就是"论文通讯作者" -- 它不亲自写每一节,但它决定"接下来把球传给谁"、"这一轮结果够不够格",以及"活干完了,投稿"。
完整代码(可直接跑)
依赖:
pip install langgraph langchain-core langchain-openai(需要OPENAI_API_KEY环境变量)
"""
clinical_paper_workflow.py
用 LangGraph 实现临床医学论文多 Agent 写作工作流
场景:写一篇 RCT(随机对照试验)论文,比较两种降压药的疗效
流程:文献检索 -> 统计分析 -> IMRAD 撰写 -> CONSORT 合规审查
概念映射:
Super Agent -> supervisor(通讯作者 / 论文主编)
SubAgent(SRP) -> literature / stats / writer / compliance
A2A 通讯 -> MessagesState(结构化消息链)
Workflow -> StateGraph(声明式 DAG)
"""
from langgraph.prebuilt import create_react_agent
from langgraph.graph import StateGraph, START, END, MessagesState
from langchain_core.tools import tool
# =========================================================
# 1. 定义每个 SubAgent 的专属 Tools
# =========================================================
@tool
def search_pubmed(query: str, max_results: int = 5) -> str:
"""Search PubMed for clinical research papers."""
# 真实场景接 NCBI E-utilities API 或 MCP PubMed server
return (
f"[PubMed results for '{query}', top {max_results}]\n"
"1. PMID:38901234 - 'Amlodipine vs Losartan in Stage 2 HTN: "
"A 12-month RCT' (Lancet 2025) - N=480, primary: 24h-ABPM\n"
"2. PMID:38876543 - 'Meta-analysis of CCB vs ARB in elderly HTN' "
"(BMJ 2024) - 12 RCTs, N=8,320\n"
"3. PMID:38765432 - 'CONSORT 2025 updated checklist for RCTs' "
"(Ann Intern Med 2025)\n"
"4. PMID:38654321 - 'Renal outcomes in ARB-treated diabetic HTN' "
"(NEJM 2024) - N=1,200\n"
"5. PMID:38543210 - 'Adverse events profiling: CCB vs ARB classes' "
"(Pharmacotherapy 2025) - systematic review"
)
@tool
def run_stats_analysis(design: str, groups: str, endpoint: str) -> str:
"""Run statistical analysis on clinical trial data."""
# 真实场景接 R/Python stats 脚本,或 MCP 数据分析 server
return (
f"[Statistical Report: {design}]\n"
f"Groups: {groups}\n"
f"Primary endpoint: {endpoint}\n\n"
"Results:\n"
"- Amlodipine group (n=240): mean SBP reduction 18.3 mmHg (SD 6.2)\n"
"- Losartan group (n=240): mean SBP reduction 16.7 mmHg (SD 5.8)\n"
"- Between-group diff: 1.6 mmHg (95% CI: 0.5-2.7, p=0.012)\n"
"- NNT for target BP (<130/80): 14\n"
"- Adverse events: peripheral edema 12.1% vs 3.3% (p<0.001)\n"
"- Kaplan-Meier 12-month adherence: 82% vs 89% (log-rank p=0.04)\n"
"- Sensitivity analysis (per-protocol): consistent with ITT"
)
@tool
def write_imrad_section(section: str, data: str) -> str:
"""Write a section of the paper in IMRAD format."""
# 真实场景用更强的模型 + 领域 prompt 模板
templates = {
"introduction": (
"## Introduction\n\n"
"Hypertension affects over 1.28 billion adults worldwide (WHO 2023). "
"Current guidelines recommend CCBs and ARBs as first-line agents, "
"yet head-to-head RCTs comparing amlodipine and losartan remain scarce...\n"
f"(Based on literature: {data[:100]}...)"
),
"methods": (
"## Methods\n\n"
"### Study design\n"
"Prospective, randomized, double-blind, active-controlled trial.\n"
"### Participants\n"
"Adults 40-75 y with stage 2 HTN (SBP 140-179 mmHg). "
"Key exclusion: secondary HTN, eGFR <30.\n"
"### Randomization\n"
"1:1 allocation via computer-generated sequence, "
"stratified by diabetes status.\n"
f"(Stats plan: {data[:80]}...)"
),
"results": (
"## Results\n\n"
f"{data}\n\n"
"Figure 1: Kaplan-Meier adherence curves.\n"
"Table 1: Baseline characteristics (well-balanced, p>0.05 for all)."
),
"discussion": (
"## Discussion\n\n"
"Our findings suggest a statistically significant but clinically modest "
"advantage of amlodipine over losartan in 24h SBP reduction. "
"However, the higher edema rate and lower adherence in the amlodipine "
"group warrant individualized treatment decisions...\n"
f"(Contextualized with: {data[:80]}...)"
),
}
return templates.get(section.lower(), f"## {section}\n\n{data}")
@tool
def check_consort_compliance(manuscript: str) -> str:
"""Check manuscript against CONSORT 2025 checklist."""
# 真实场景:逐条比对 CONSORT 25 项 + 流程图
return (
"CONSORT 2025 Compliance Report:\n\n"
"PASS [1] Title: identified as randomised trial\n"
"PASS [2] Abstract: structured, includes key numbers\n"
"PASS [3a] Background: scientific rationale stated\n"
"WARN [6a] Outcomes: secondary endpoints not fully pre-specified\n"
"PASS [7a] Sample size: calculation provided (power=0.80, alpha=0.05)\n"
"PASS [8a] Randomization: sequence generation described\n"
"WARN [11a] Blinding: assessor blinding not explicitly confirmed\n"
"PASS [13a] Flow diagram: CONSORT flow present\n"
"PASS [16] Ancillary analyses: sensitivity analysis included\n"
"FAIL [23] Registration: trial registry number missing\n\n"
"Score: 22/25 items PASS, 2 WARN, 1 FAIL\n"
"Action required: add trial registration number (e.g. NCT0xxxxxxx)"
)
# =========================================================
# 2. 定义四个 SubAgent(SRP:一个 Agent 只干一件事)
# =========================================================
literature_agent = create_react_agent(
model="openai:gpt-4o-mini",
tools=[search_pubmed],
prompt=(
"你是 LiteratureAgent,只负责在 PubMed 检索相关临床文献。"
"输出结构化的参考列表:PMID、标题、期刊、年份、样本量、关键结论。"
"不要写论文正文,不要做统计分析。"
),
name="literature_agent",
)
stats_agent = create_react_agent(
model="openai:gpt-4o-mini",
tools=[run_stats_analysis],
prompt=(
"你是 StatsAgent,只负责对临床试验数据做统计分析。"
"输出:主要终点结果、p 值、置信区间、效应量、敏感性分析。"
"不要写论文正文,不要检索文献。"
),
name="stats_agent",
)
writer_agent = create_react_agent(
model="openai:gpt-4o-mini",
tools=[write_imrad_section],
prompt=(
"你是 WriterAgent,根据文献和统计结果撰写论文。"
"严格使用 IMRAD 结构(Introduction, Methods, Results, Discussion)。"
"学术语言,客观严谨,引用须标注 PMID。"
"不要自己编造数据,只用已有的文献和统计结果。"
),
name="writer_agent",
)
compliance_agent = create_react_agent(
model="openai:gpt-4o-mini",
tools=[check_consort_compliance],
prompt=(
"你是 ComplianceAgent,按 CONSORT 2025 清单审查论文手稿。"
"逐条检查并输出:PASS / WARN / FAIL + 具体修改建议。"
"不要自己改写论文,只输出审查报告。"
),
name="compliance_agent",
)
# =========================================================
# 3. 定义 Supervisor(通讯作者:编排 + 质控)
# =========================================================
supervisor_agent = create_react_agent(
model="openai:gpt-4o-mini",
tools=[], # supervisor 不需要 tools,它靠路由决策
prompt=(
"你是 Supervisor(通讯作者),管理四个 Agent:\n"
"1. literature_agent - 负责 PubMed 文献检索\n"
"2. stats_agent - 负责统计分析\n"
"3. writer_agent - 负责 IMRAD 论文撰写\n"
"4. compliance_agent - 负责 CONSORT 合规审查\n\n"
"标准流程:\n"
" Step 1: literature_agent 检索相关 RCT 和 meta-analysis\n"
" Step 2: stats_agent 分析试验数据\n"
" Step 3: writer_agent 按 IMRAD 撰写各章节\n"
" Step 4: compliance_agent 做 CONSORT 合规检查\n\n"
"每次只分派一个任务。如果合规审查有 FAIL 项,"
"把修改意见转给 writer_agent 修订,然后重新审查。\n"
"全部 PASS 或仅剩 WARN 后,输出最终结论并结束。"
),
name="supervisor",
)
# =========================================================
# 4. 组装 StateGraph -- 声明式 workflow
# =========================================================
workflow = (
StateGraph(MessagesState)
.add_node(
supervisor_agent,
destinations=(
"literature_agent", "stats_agent",
"writer_agent", "compliance_agent", END
),
)
.add_node(literature_agent)
.add_node(stats_agent)
.add_node(writer_agent)
.add_node(compliance_agent)
.add_edge(START, "supervisor")
# 每个 SubAgent 完成后回到 supervisor
.add_edge("literature_agent", "supervisor")
.add_edge("stats_agent", "supervisor")
.add_edge("writer_agent", "supervisor")
.add_edge("compliance_agent", "supervisor")
.compile()
)
# =========================================================
# 5. 执行 -- 一句话触发整个论文写作流程
# =========================================================
if __name__ == "__main__":
result = workflow.invoke(
{
"messages": [
{
"role": "user",
"content": (
"请帮我写一篇 RCT 论文:比较氨氯地平与氯沙坦"
"治疗 2 期高血压的 12 个月疗效和安全性。"
"样本量 480 例,主要终点为 24 小时动态血压。"
),
}
]
}
)
for msg in result["messages"]:
role = getattr(msg, "type", "unknown")
content = getattr(msg, "content", "")
if content:
print(f"[{role}] {content[:200]}")
print("---")
几个值得注意的设计细节
为什么拆成四个 Agent 而不是一个大 Prompt?
你当然可以把"检索 + 统计 + 写作 + 合规"塞进一个 system prompt。但那样一来:改 CONSORT 检查项就得动整个 prompt,牵一发而动全身;stats_agent 想换个更擅长数值推理的模型(比如 o3)?没门,因为和写作共用一个上下文;合规审查 FAIL 了?只能整篇重跑,而不是只让 writer_agent 改那一节。
拆开之后,这些问题都不存在了——每个 Agent 独立演进、独立替换、独立重试。这就是 SRP 在 Agent 场景下的实际收益。
Supervisor 的"循环修订"能力
注意 supervisor prompt 里的这段:"如果合规审查有 FAIL 项,把修改意见转给 writer_agent 修订,然后重新审查"。这不是线性流水线,而是带反馈环的 DAG -- LangGraph 天然支持,因为每个 SubAgent 完成后都回到 supervisor,由它决定是"往下走"还是"打回去"。
MessagesState 就是"穷人版 A2A"
LangGraph 的 MessagesState 是一个共享的结构化消息列表。每个节点读到的输入、写出的输出都挂在这条链上 -- 天然带了顺序、角色标记(谁说的)和内容。如果你需要更严格的 schema 校验,可以继承 MessagesState 加自己的字段:
from typing import List, Optional
class ClinicalPaperState(MessagesState):
"""扩展 state,让论文写作的 A2A 数据更结构化"""
references: List[dict] # LiteratureAgent: PMID + 摘要
stats_report: str # StatsAgent: 统计分析报告
manuscript_sections: dict # WriterAgent: {"intro": ..., "methods": ...}
consort_score: Optional[dict] # ComplianceAgent: {pass: 22, warn: 2, fail: 1}
revision_round: int # 第几轮修订(可观测性)
Prompt 怎么从文件加载?
把前面第 3 节讲的 "Prompt 版本管理" 接上:
from pathlib import Path
def load_prompt(agent_name: str, version: str = "v1") -> str:
"""从 prompts/ 目录加载对应版本的 system prompt"""
path = Path(f"prompts/agents/{agent_name}/system.{version}.md")
return path.read_text(encoding="utf-8")
# 用法:升级 CONSORT 检查清单时,只需要改 compliance 的 prompt 文件
compliance_agent = create_react_agent(
model="openai:gpt-4o-mini",
tools=[check_consort_compliance],
prompt=load_prompt("compliance", "v2"), # CONSORT 2025 版
name="compliance_agent",
)
MCP 怎么接进来?
LangGraph 的 @tool 装饰器可以包装任何 Python 函数。如果你的 PubMed 检索工具跑在 MCP Server 上,只需要写一个适配层:
from mcp import ClientSession
@tool
async def mcp_pubmed_search(query: str, max_results: int = 5) -> str:
"""通过 MCP Server 检索 PubMed(替代直接调 NCBI API)"""
async with ClientSession(transport) as session:
result = await session.call_tool(
"pubmed_search",
arguments={"query": query, "max_results": max_results}
)
return result.content[0].text
这样 literature_agent 代码不用改,只是 tool 的实现从"直接调 NCBI E-utilities"变成了"走 MCP 协议" -- 接口不变,通道标准化。同理,stats_agent 的统计脚本也可以包成 MCP Server,让 R/Python 后端跑真实的 t-test / Cox regression。
总结:复杂流程的解法,是"工程化地管理不确定性"
如果你只记住一句话:Super Agent 负责编排与验收,SubAgent 负责 SRP 能力,A2A 用契约沟通,Prompt 用 Git 管版本,Workflow 先声明后执行,MCP 把工具接入标准化。
你目前团队里最想用 Agent 处理的"复杂流程"是什么?是代码审查、安全审计、内容生产,还是别的什么?欢迎留言聊聊——说不定你的场景就是下一篇文章的素材。
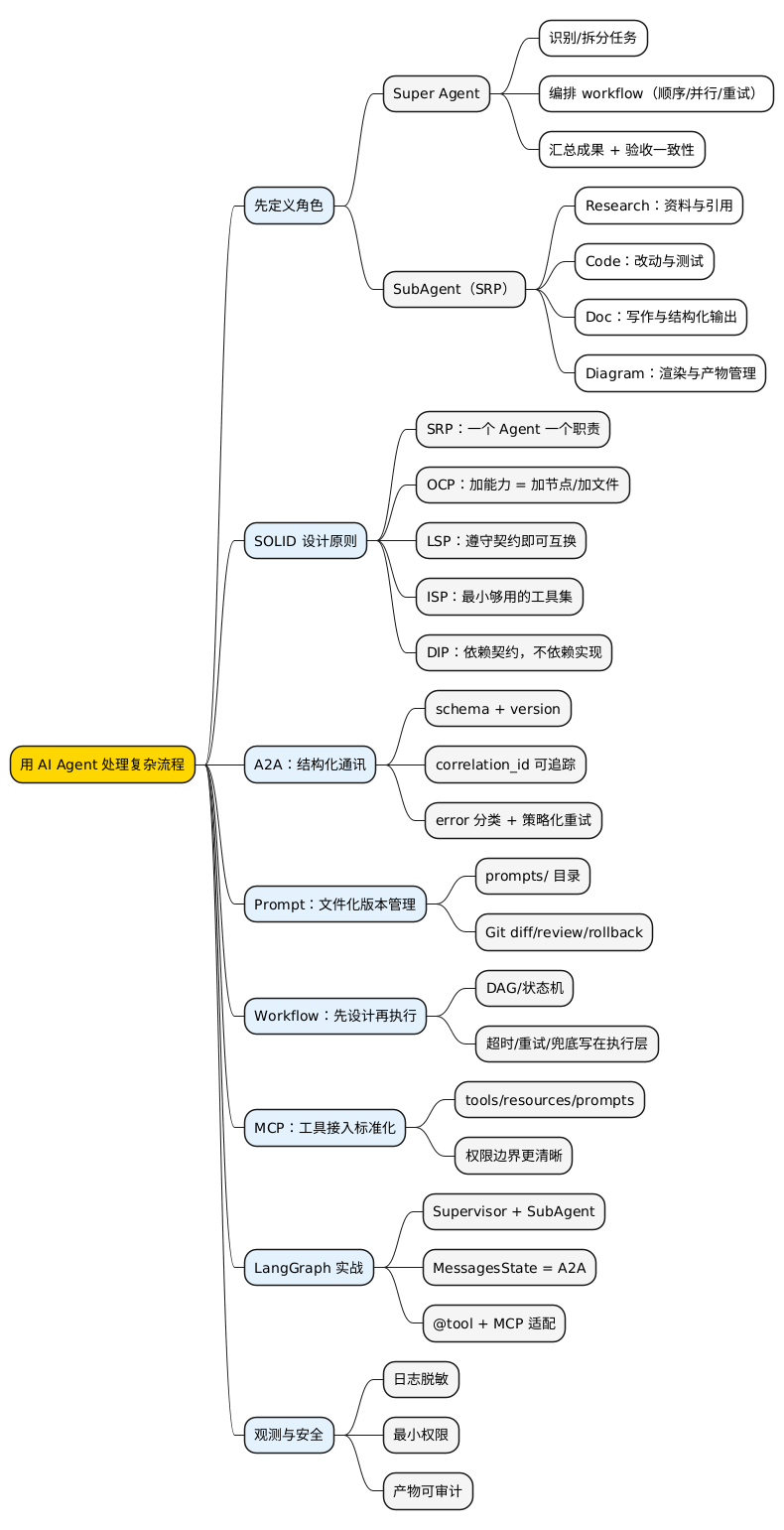
最后给你一张思维导图(方便复盘/分享给同事)。
@startmindmap
<style>
mindmapDiagram {
node {
BackgroundColor #FAFAFA
}
:depth(0) {
BackgroundColor #FFD700
}
:depth(1) {
BackgroundColor #E3F2FD
}
:depth(2) {
BackgroundColor #F5F5F5
}
}
</style>
* 用 AI Agent 处理复杂流程
** 先定义角色
*** Super Agent
**** 识别/拆分任务
**** 编排 workflow(顺序/并行/重试)
**** 汇总成果 + 验收一致性
*** SubAgent(SRP)
**** Research:资料与引用
**** Code:改动与测试
**** Doc:写作与结构化输出
**** Diagram:渲染与产物管理
** SOLID 设计原则
*** SRP:一个 Agent 一个职责
*** OCP:加能力 = 加节点/加文件
*** LSP:遵守契约即可互换
*** ISP:最小够用的工具集
*** DIP:依赖契约,不依赖实现
** A2A:结构化通讯
*** schema + version
*** correlation_id 可追踪
*** error 分类 + 策略化重试
** Prompt:文件化版本管理
*** prompts/ 目录
*** Git diff/review/rollback
** Workflow:先设计再执行
*** DAG/状态机
*** 超时/重试/兜底写在执行层
** MCP:工具接入标准化
*** tools/resources/prompts
*** 权限边界更清晰
** LangGraph 实战
*** Supervisor + SubAgent
*** MessagesState = A2A
*** @tool + MCP 适配
** 观测与安全
*** 日志脱敏
*** 最小权限
*** 产物可审计
@endmindmap
扩展阅读
- Model Context Protocol(MCP)规范(latest)
- Model Context Protocol 官方站点
- MCP GitHub Organization(参考实现与 SDK)
- LangGraph 官方文档
- LangGraph Multi-Agent Supervisor Tutorial
- Google Agent2Agent Protocol (A2A)
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。