如何打造个人与项目知识库:从全文搜索到 RAG,再到 Claude Skill
Posted on Thu 05 February 2026 in Journal
| Abstract | 如何打造个人与项目知识库:从全文搜索到 RAG,再到 Claude Skill |
|---|---|
| Authors | Walter Fan |
| Category | 方法与工具 |
| Status | v1.0 |
| Updated | 2026-02-05 |
| License | CC-BY-NC-ND 4.0 |
你有没有这种瞬间:
- 需求评审会上,产品一句“上次我们怎么处理的来着?”你脑子里闪过 10 个微信群、3 个文档平台、2 个 repo……最后只憋出一句:“我回去找找。”
- 你明明写过一篇笔记(甚至写得挺好),但三个月后再遇到类似问题,还是从 Google/搜索引擎重新搜一遍,像从没学过一样。
反直觉的一点是:知识库最难的不是“写”,而是“找得到、用得上、跟得上”。
所以我建议别一上来就“搞 RAG”,先把最土、但最管用的三件事做扎实:
1) 全文搜索(能找)
2) 结构化摘要(能用)
3) 自动化入口(能复用,能交付给未来的自己)
下面我用“个人知识库”和“项目知识库”两条线,给一套可落地的路线图。你不需要一次做完,按阶段升级就行。
短大纲(先看 30 秒,决定要不要继续读)
- 为什么多数知识库死在第 0 步:写得多,找不到 - 第一阶段:全文搜索(最便宜的生产力) - 第二阶段:RAG(别神化,它就是“检索 + 拼接”) - 第三阶段:把方法封装成 Claude Skill / Cursor command(让自己不再重复劳动) - 个人知识库 vs 项目知识库:目录结构、权限边界、更新策略 - Checklist:从“能搜”到“能交付”的自检清单一、别神化 RAG:你缺的往往是“检索”,不是“模型”
我见过不少同事的知识库开局是这样的:
“我搞个向量库,把所有文档灌进去,问啥都能答。”
(三天后)“怎么回答还不如我自己搜?”
这并不奇怪。RAG(Retrieval-Augmented Generation)再高级,本质也只解决一件事:在你给大模型的上下文里,塞进更相关的材料。
如果你连“材料在哪里、怎么检索、是否可信、是否最新”都没搞清楚,那 RAG 只会把问题放大:你会得到一堆看起来很像答案的“拼接作文”。
所以顺序最好是:
- 先把资料变得可搜索(全文搜索)
- 再把资料变得可复用(摘要、卡片、模板)
- 最后才谈自动回答(RAG)
二、第一阶段:全文搜索——最便宜、回报最快的知识库能力
2.1 个人知识库:用 Markdown + Git,把“可迁移”放在第一位
我推荐个人知识库尽量“朴素”:
- 格式:Markdown(可迁移、可 diff、可 code review)
- 存储:Git(历史可追溯,改坏能回滚)
- 命名:日期 + 主题(你现在 blog/journal 的方式就很好)
你甚至不用先选“笔记软件”。真正影响你体验的,是这两件事:
- 文件路径能不能表达语义(比如
content/journal/、doc/source/5.work/) - 你有没有一个统一的检索入口
检索入口怎么做?最简单的就是命令行全文搜索:
rg(ripgrep):速度快、正则强、默认就很好用- 配合你习惯的编辑器(比如 Cursor/VSCode)全局搜索,够你用很久
如果你偏好“像搜索引擎一样”的体验(带权重、拼写纠错、过滤条件),可以再升级到:
- SQLite FTS5(轻量、单机、适合个人/小团队)
- Meilisearch / Elasticsearch(更像“搜索服务”,运维成本也更像)
但请注意:不要为了上技术而上技术。大多数个人知识库,做到“1 秒内搜到答案”就已经赢了。
2.2 项目知识库:把“知识”放回 repo,让它和代码一起演进
项目知识库最常见的死法是:文档放在某个云盘或平台上,代码在另一个地方,大家都很忙,最后两边不同步。
一个更务实的做法是:
- 关键文档放回 repo(比如
docs/、doc/source/) - 写清楚入口文件(比如
README.md、AGENTS.md、CLAUDE.md) - 让文档变成“交付物”,可以被 review(PR/MR 里一起看)
我特别建议你在每个项目里至少放三类东西:
- What:这个项目是干嘛的(给新人看的)
- How:怎么跑、怎么发布、怎么排查(给未来的你看的)
- Why:关键决策为什么这么做(给“半年后的你 + 评审的人”看的)
三、第二阶段:RAG——把“能搜”升级为“能问”,但别越过边界
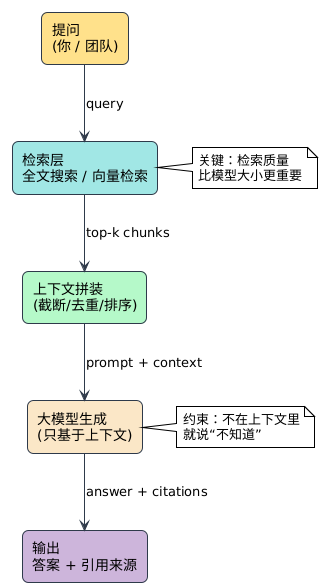
3.1 一句话讲清 RAG:检索 + 拼接 + 约束
RAG 你可以理解为一个很朴素的流水线:
1) 你提问
2) 系统去你的资料库里“捞”出最相关的片段
3) 把片段塞给大模型,让它在这些片段里作答
4) 用引用/来源约束它别乱编
下面这张图可以当作你搭 RAG 时的“施工蓝图”。
@startuml
!theme plain
skinparam backgroundColor #FEFEFE
skinparam DefaultFontName PingFang SC
skinparam ArrowColor #2F3A4A
skinparam RectangleBorderColor #2F3A4A
skinparam RectangleRoundCorner 12
rectangle "提问\n(你 / 团队)" as Q #FFE08A
rectangle "检索层\n全文搜索 / 向量检索" as R #A0E7E5
rectangle "上下文拼装\n(截断/去重/排序)" as C #B4F8C8
rectangle "大模型生成\n(只基于上下文)" as LLM #FBE7C6
rectangle "输出\n答案 + 引用来源" as A #CDB4DB
Q -down-> R : query
R -down-> C : top-k chunks
C -down-> LLM : prompt + context
LLM -down-> A : answer + citations
note right of R
关键:检索质量
比模型大小更重要
end note
note right of LLM
约束:不在上下文里
就说“不知道”
end note
@enduml
3.2 RAG 最容易踩的三个坑(我建议你提前规避)
-
坑 1:切块(chunking)随缘
切太大:上下文塞不下;切太小:信息断裂,模型“看不懂”。
经验上,先从“按小标题切 + 控制每块字数”开始,别一上来就追求最优参数。 -
坑 2:资料没“新鲜度”策略
旧设计、旧接口、旧结论混在一起,你问一次就可能被“考古学”绊倒。
最实用的做法是:每个片段带上来源 + 日期 + 版本,并且定期做“过期清理”。 -
坑 3:权限边界没画清楚
个人知识库可以随便灌;项目知识库往往涉及内部信息、客户信息、账号信息。
原则很简单:不能公开的内容,就别进会外发的系统;需要进系统,也要做脱敏/访问控制。
四、第三阶段:把方法封装成 Claude Skill / Cursor command——让知识库“可复用”
如果说“知识库”是你的仓库,那 Skill/Command 就是你仓库门口那把钥匙:
你不需要每次都绕路走后门,按一个开关就能进。
4.1 个人场景:把常见问题变成“可重复的工作流”
我建议你先挑 3 类最高频的动作做自动化(越具体越好):
- 写作类:把零散笔记加工成结构化文章(例如你现在的
/blog-write) - 总结类:把一周的 commit / issue / 笔记汇总成 4D 总结
- 排查类:把日志/代码片段解释清楚,顺手给排查路径
Skill/Command 的价值不是“生成文本”,而是:
- 固定输入(你每次要提供什么)
- 固定输出(给你一个可交付的结果)
- 固定约束(哪些不能做、哪些必须保留)
这也是为什么它特别适合当“项目知识库”的入口:流程固化了,团队就不靠口口相传。
4.2 项目场景:让仓库自己“会说话”
你这个 blog 项目里已经有很好的雏形:
.cursor/commands/:把常用写作流程做成命令.claude/skills/:把能力做成可复用技能CLAUDE.md/AGENTS.md:把“项目结构 + 写作风格 + 约束”写清楚
这套组合拳的效果是:你换一台电脑、换一个编辑器、甚至换一个团队成员,知识库仍然能跑起来。
五、个人知识库 vs 项目知识库:我建议你用两条“数据流”
我会把两者分开管理,避免互相污染:
-
个人知识库:更像“训练场”
你可以记录不成熟的想法、失败复盘、半成品模板。重点是“你能找回来”。 -
项目知识库:更像“产品说明书 + 运维手册”
强调可复现、可审计、可协作。重点是“别人也能用”。
一个小技巧:
个人笔记可以写得随意,但项目知识库要写得“可交付”。
比如同样是排查记录,项目里要补上版本、环境、复现步骤、结论与行动项。
六、Checklist:从“能搜”到“能交付”的 10 秒自检
- [ ] 能搜到:同一个问题,1 分钟内能定位到材料
- [ ] 能看懂:材料里有背景、结论、适用边界(不是只有一段聊天截图)
- [ ] 能复用:有模板/脚本/命令,下一次不用从头做
- [ ] 能更新:有“过期策略”(日期/版本/Owner)
- [ ] 能引用:答案能指回来源(文档/PR/commit/链接)
- [ ] 不越界:敏感信息有边界(不进外发系统、不进日志、不进公开仓库)
七、总结:知识库不是“记忆宫殿”,是“可检索的工作流”
如果你只记住一句话,那就记这个:
先把检索做对,再谈 RAG;最后用 Skill/Command 把流程固化。
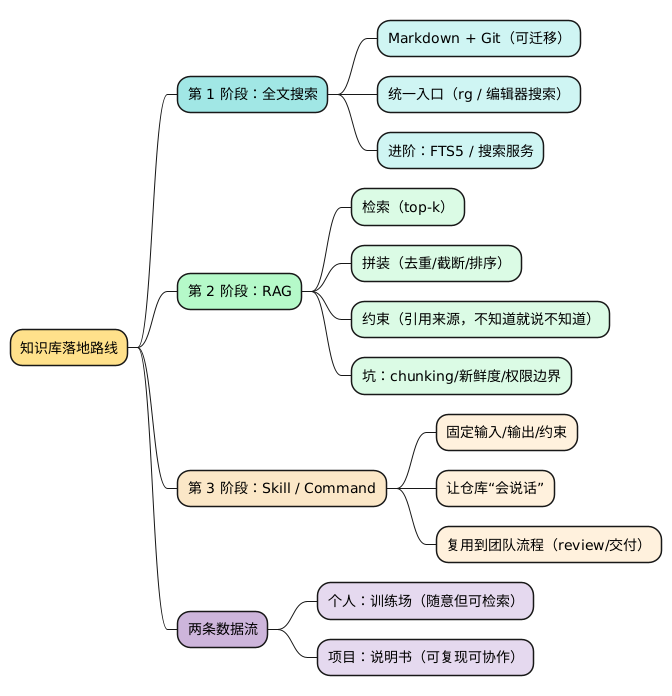
思维导图(方便你转发给同事)
@startmindmap
skinparam NodeMargin 2
skinparam Padding 2
*[#FFE08A] 知识库落地路线
**[#A0E7E5] 第 1 阶段:全文搜索
***[#CFF5F3] Markdown + Git(可迁移)
***[#CFF5F3] 统一入口(rg / 编辑器搜索)
***[#CFF5F3] 进阶:FTS5 / 搜索服务
**[#B4F8C8] 第 2 阶段:RAG
***[#DBFBE5] 检索(top-k)
***[#DBFBE5] 拼装(去重/截断/排序)
***[#DBFBE5] 约束(引用来源,不知道就说不知道)
***[#DBFBE5] 坑:chunking/新鲜度/权限边界
**[#FBE7C6] 第 3 阶段:Skill / Command
***[#FFF1DC] 固定输入/输出/约束
***[#FFF1DC] 让仓库“会说话”
***[#FFF1DC] 复用到团队流程(review/交付)
**[#CDB4DB] 两条数据流
***[#E5D9EE] 个人:训练场(随意但可检索)
***[#E5D9EE] 项目:说明书(可复现可协作)
@endmindmap
扩展阅读
- ripgrep - 速度很快的全文搜索工具
- SQLite FTS5 - 轻量全文搜索引擎
- PlantUML - 用代码画图(适合放进 repo)
- Ragas - RAG 评估工具(想严谨一点可以看看)
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。