如何让 AI 真正“懂”你的项目?一套可落地的项目知识包
Posted on Mon 16 February 2026 in AI 方法论
| Abstract | 如何让 AI 真正“懂”你的项目?Project Knowledge Pack 方法论 |
|---|---|
| Authors | Walter Fan |
| Category | AI 方法论 |
| Version | v1.0 |
| Updated | 2026-02-16 |
| License | CC-BY-NC-ND 4.0 |
如何让 AI 真正“懂”你的项目?一套可落地的项目知识包
你扔给 AI 一坨代码,让它“帮忙改个需求”。它要么泛泛而谈,要么改完一跑测试全红,要么提的方案你们三年前就否了、ADR 里写得明明白白——可 AI 没读过。
问题不在 AI 笨,而在:你的项目从来没有被工程化地“喂”给它。 做不到“让 AI 一次性彻底理解一切并永久记住”,但可以退而求其次:把项目做成一个可被 AI 消化的知识包(Project Knowledge Pack),再配合迭代式对话与自动化索引(RAG / 代码检索 / 文档生成),效果可以非常接近“项目专家 + 能上手开发测试的工程师”。
下面是一套可落地的方法论与清单。
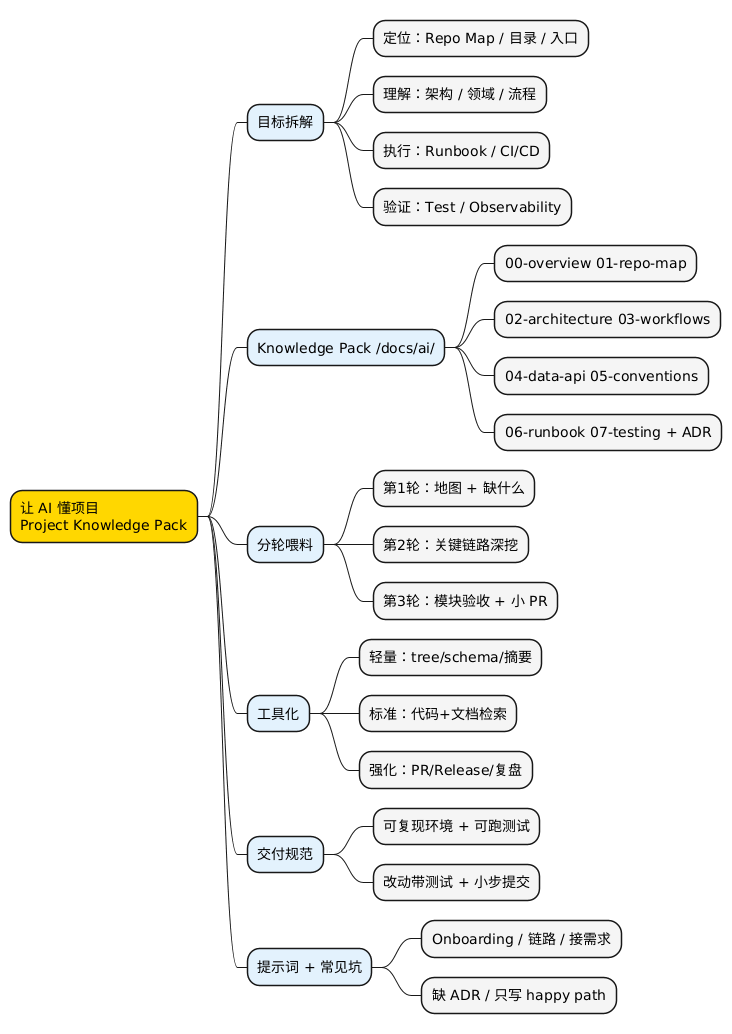
一、目标拆解:AI 要“像工程师一样”需要哪四类能力?
先把“专家”拆开,再按能力准备材料,就不会漏项。
| 能力 | 含义 | 你要准备的材料 |
|---|---|---|
| 定位 | 快速知道代码/配置/脚本在哪 | Repo Map、目录树、关键入口 |
| 理解 | 懂架构、依赖、数据流、业务流 | Architecture、Domain、流程说明 |
| 执行 | 能拉起环境、跑测试、改代码、提 PR | Runbook、CI/CD、一键命令 |
| 验证 | 能设计测试、定位 bug、做回归 | Test Strategy、Observability、日志/trace |
你的输入资料就围绕这四类组织,AI 才能既“看得懂”又“动得了手”。
二、最重要的产物:Project Knowledge Pack(建议放在仓库 man/)
建议在仓库里建一个 man/ 目录(用 Sphinx + MyST 构建,或 wiki),放一套最小闭环文档。每份尽量短、结构化、能链接到具体代码位置。同时可在 man/ 下建 changes/ 目录,按 OpenSpec 风格管理变更提案(见下文 J)。
A. 项目总览(00-overview.md)
- 项目目的、业务边界、不做什么
- 关键用户角色与核心用例
- 技术栈:语言、框架、中间件、数据库
- 部署形态:单体 / 微服务 / 多端
- 性能 / 一致性 / 可用性目标(SLO)
B. Repo Map(01-repo-map.md)
- 目录树(到 2~3 层)
- 每个目录的职责
- 关键入口:main、app、router、DI 容器、配置加载
- 约定:命名、分层、常见模式(如 CQRS、DDD、Clean Architecture)
C. 架构与模块(02-architecture.md)
- 组件图(服务/模块边界)
- 关键调用链(从入口到 DB / 外部 API)
- 模块依赖规则(谁允许依赖谁)
- 横切关注点:鉴权、日志、错误码、事务、缓存、重试、幂等
D. 业务流程(03-workflows.md)
按用例写,每条包含:
- 流程步骤(可用时序图/状态机)
- 输入输出、关键校验、异常分支
- 涉及的表/消息/事件
- 关键代码入口(文件路径 + 函数名)
E. 数据模型与 API 契约(04-data-and-api.md)
- 数据库:核心表/字段、索引、约束、迁移工具
- 领域对象与 DTO 的映射规则
- 外部接口:OpenAPI / GraphQL schema / Proto 的链接
- 事件/消息:topic、schema、兼容性策略
F. 工程习惯用法(05-conventions.md)
- 代码风格、lint / format
- 错误处理、日志字段、traceId
- 配置管理:env、config file、secret
- Feature flag、灰度、版本策略
- 反模式清单:哪些写法禁止、为什么
G. 环境与操作手册(06-runbook.md)
- 一键启动:docker compose / devcontainer / make
- 如何跑全部测试 / 单测 / 集成 / E2E
- 本地调试:端口、依赖、mock
- 常见故障排查:DB 连接、迁移失败、权限、缓存脏数据
H. 测试策略(07-testing.md)
- 测试金字塔:单测 / 契约 / 集成 / E2E 的范围
- 关键路径的测试用例清单
- 测试数据构造与隔离策略
- 覆盖率门槛与 flaky 处理
I. ADR(架构决策记录,man/source/adr/)
每次重要决策一条:背景、候选方案、取舍、后果。AI 非常依赖 ADR 理解“为什么这样设计”,否则会反复提出你们早就否掉的方案。
J. changes(变更提案,man/changes/)
与 OpenSpec 工作流一致:每个变更一个子目录(如 add-xxx、update-xxx),包含:
proposal.md:为什么改、改什么、影响面(Why / What Changes / Impact)design.md(可选):技术决策、目标与非目标、风险与迁移tasks.md:实施清单(可勾选跟踪进度)specs/<capability>/spec.md:对受影响能力的规格增量(## ADDED|MODIFIED|REMOVED Requirements,每条至少一个#### Scenario:)
便于人与 AI 按「提案 → 设计 → 任务 → 规格」推进;若项目根有 openspec/ 与 CLI,可用 openspec validate <change-id> --strict 校验。模板见 man/changes/_template/。
三、让 AI “读得懂”的输入方式:从宏观到微观,分三轮喂
不要一次把所有代码贴给 AI。更高效的是分三轮,每轮有明确产出。
第 1 轮:建立“地图”
你提供: 00-overview + 01-repo-map + 架构图
让 AI 输出: 模块清单、入口点清单、关键数据流总结、它还缺哪些信息(按优先级)
第 2 轮:挑 2~3 条关键业务链路深挖
每条链路你提供:流程文档 + 相关代码目录(或关键文件)
让 AI 输出: 调用路径、潜在边界条件、可测试点、风险点
第 3 轮:按模块逐个“验收理解”
对每个模块:输入模块 README(职责、API、依赖、示例)+ 该模块的测试与样例数据
让 AI 输出: 改进建议,并完成一个小改动(真实 PR 级别,带测试)
四、工具化:把仓库变成可检索知识库(RAG / 索引)
如果希望 AI 长期、稳定地像“项目专家”一样工作,可以按项目规模选一档:
- 轻量(小中型项目):定期生成
tree、依赖图、OpenAPI、DB schema 摘要、关键调用链,放进man/,作为“权威资料”给 AI 引用。 - 标准(中大型):代码按文件/符号索引(ctags、LSP、Sourcegraph 等),文档(Markdown / ADR / 接口)入库;AI 通过检索拿到“相关片段 + 位置”,再生成修改方案与补丁。
- 强化(企业级):PR 自动生成变更摘要、影响面、测试建议;Release 生成变更说明与回归清单;把 incident / 故障复盘也沉淀为可检索知识。
五、让 AI 能“真正干活”:开发 / 测试闭环
要让 AI 像工程师一样承担开发和测试,关键是:
- 可复现环境:一条命令启动依赖与服务(Docker Compose / DevContainer)
- 可运行测试:一条命令跑单测 / 集成 / E2E,且与 CI 一致
- 可观测:日志、trace、错误码清晰,能定位问题
- 可约束:lint / format / typecheck / commit hooks,减少“写坏代码”的空间
- 可小步提交:要求 AI 每次改动小、带测试、带说明
可以定一个 AI 交付规范:
- 每次输出必须包含:改动点列表、涉及文件、风险、测试计划、回滚方式
- 每次改动必须补齐:至少一个单测或集成测试
- 不允许“只改业务不改测试”
六、可直接用的提示词(复制即用)
让 AI 做项目 Onboarding
你将作为本项目的资深工程师。下面是项目 Overview、Repo Map、Architecture。
任务:
1) 用 1 页总结系统的组件、入口、关键数据流。
2) 列出你还缺的 10 个关键信息(按优先级)。
3) 提出一个你认为最适合作为“第一个上手改动”的小任务(包含测试)。
让 AI 深入某条业务链路
下面是“某流程”的流程说明 + 相关代码文件。
任务:
1) 画出调用链(函数/模块级别),并标注事务边界、幂等点、重试点。
2) 指出 5 个最可能出 bug 的边界条件。
3) 给出完整测试清单(单测/集成/E2E),并说明每类测什么。
让 AI 接一个真实需求
需求:……(验收标准、约束)
请按步骤输出:设计方案 → 影响面 → 需要改哪些文件 → 需要补哪些测试 → 风险与回滚 → 最小可行 PR 计划(分 2~3 个提交)。
七、常见坑(提前规避)
- 只有代码没有“为什么”:缺 ADR,AI 会反复提出不符合历史取舍的方案。
- 流程只写 happy path:AI 会漏掉异常分支与补偿逻辑。
- 没有可运行的集成测试:AI 很难验证修改是否真实可用。
- 环境不可复现:AI 和新人都无法稳定上手。
八、总结与行动清单
把“让 AI 懂项目”当成一项工程来做:先拆能力(定位/理解/执行/验证),再准备 Knowledge Pack(overview、repo map、架构、流程、数据与 API、规范、runbook、测试、ADR),然后分三轮从宏观到微观喂料,辅以工具化索引与明确的交付规范。 这样 AI 才能既读懂上下文,又能动手改代码、补测试。
思维导图
@startmindmap
<style>
mindmapDiagram {
node { BackgroundColor #FAFAFA }
:depth(0) { BackgroundColor #FFD700 }
:depth(1) { BackgroundColor #E3F2FD }
:depth(2) { BackgroundColor #F5F5F5 }
}
</style>
* 让 AI 懂项目\nProject Knowledge Pack
** 目标拆解
*** 定位:Repo Map / 目录 / 入口
*** 理解:架构 / 领域 / 流程
*** 执行:Runbook / CI/CD
*** 验证:Test / Observability
** Knowledge Pack man/
*** 00-overview 01-repo-map
*** 02-architecture 03-workflows
*** 04-data-api 05-conventions
*** 06-runbook 07-testing + ADR
*** changes: proposal/design/tasks/spec
** 分轮喂料
*** 第1轮:地图 + 缺什么
*** 第2轮:关键链路深挖
*** 第3轮:模块验收 + 小 PR
** 工具化
*** 轻量:tree/schema/摘要
*** 标准:代码+文档检索
*** 强化:PR/Release/复盘
** 交付规范
*** 可复现环境 + 可跑测试
*** 改动带测试 + 小步提交
** 提示词 + 常见坑
*** Onboarding / 链路 / 接需求
*** 缺 ADR / 只写 happy path
@endmindmap
明天就能做的 3 件事
- 建
man/并写00-overview.md:用一页写清项目目的、技术栈、部署形态、核心用例;写完后让 AI 读一遍,看它列出的“缺的 10 条信息”是否合理。 - 补一份
01-repo-map.md:用tree -L 3打底,给每个目录一句话职责,标出 main/app/router 等入口;和团队对齐命名与分层约定。 - 选一条核心流程写进
03-workflows.md:从请求入口到 DB/外部 API,包含异常分支;附上关键文件路径和函数名,再让 AI 画调用链并指出 5 个风险点,验证它是否真能“跟上”。
适用边界
- 适合:希望 AI 长期参与开发、做 Code Review、接小需求或补测试的团队;中大型仓库、多模块/多服务尤其受益。
- 不太适合:一次性问一句就跑的临时问题;没有文档、没有测试、环境都拉不起来的“祖传仓库”(先还技术债再谈 AI)。
- 代价:前期要花时间整理文档和 runbook;文档会变成“活文档”,需要随代码一起维护,否则 AI 会基于过期信息给建议。
一个开放式结尾
你们团队现在有没有一份“新人 + AI 共用”的 onboarding 清单?如果有,第一条是什么?如果没有,你打算从 Repo Map 还是从一条核心流程开始?
扩展阅读
- Architecture Decision Records (ADR)(ADR 的规范与示例)
- DevContainer 规范(可复现开发环境)
- Backstage / 内部开发者门户(中大型团队的项目与文档门户)
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。