从 Prompt Engineering 到 Harness Engineering:AI 编程的四次进化
Posted on 六 28 3月 2026 in Tech
| Abstract | 从 Prompt Engineering 到 Harness Engineering |
|---|---|
| Authors | Walter Fan |
| Category | AI Engineering |
| Status | v1.0 |
| Updated | 2026-03-28 |
| License | CC-BY-NC-ND 4.0 |
百万行代码,零行手写
2026 年 2 月,OpenAI 发了一篇博文,标题叫 Harness Engineering: Leveraging Codex in an Agent-First World。文章说的事情挺吓人:他们的 Codex 团队用五个月时间,从一个空仓库开始,生成了超过一百万行生产代码——零行是人手写的。这个产品有内部日活用户,有外部 alpha 测试者,能自动部署、自动修复、自动迭代。
更有意思的是结论:最难的不是 Agent,而是 Harness。
Harness 这个词,本意是"马具"——笼头、缰绳、马鞍、马镫这一整套。
LLM 就像一匹烈马,天生神力,日行千里,可脾气也大——你让它写代码,它可能写出惊艳的架构,也可能一路狂奔跑进死胡同,甚至尥蹶子把你甩下来。光靠嘴吆喝(Prompt)管不住它,光给它看地图(Context)也不够。要驯服这匹烈马,你得给它套上一整套马具:缰绳控制方向(CLAUDE.md、架构规则),马鞍让你坐稳(Skill 定义、标准化工作流),围栏圈定跑道(Linter、Hook、CI/CD),马夫定期打理马厩(巡检 Agent、依赖审计)。
这就是 Harness Engineering——不是教 AI 怎么跑,而是搭一套让它跑得又快又稳的环境。OpenAI 把这个理念提炼成了方法论:设计约束、反馈回路和基础设施,让 AI Agent 在可控范围内可靠地工作。
咱们来聊聊这事儿的来龙去脉。
四次进化:从教 AI 说话到给 AI 搭环境
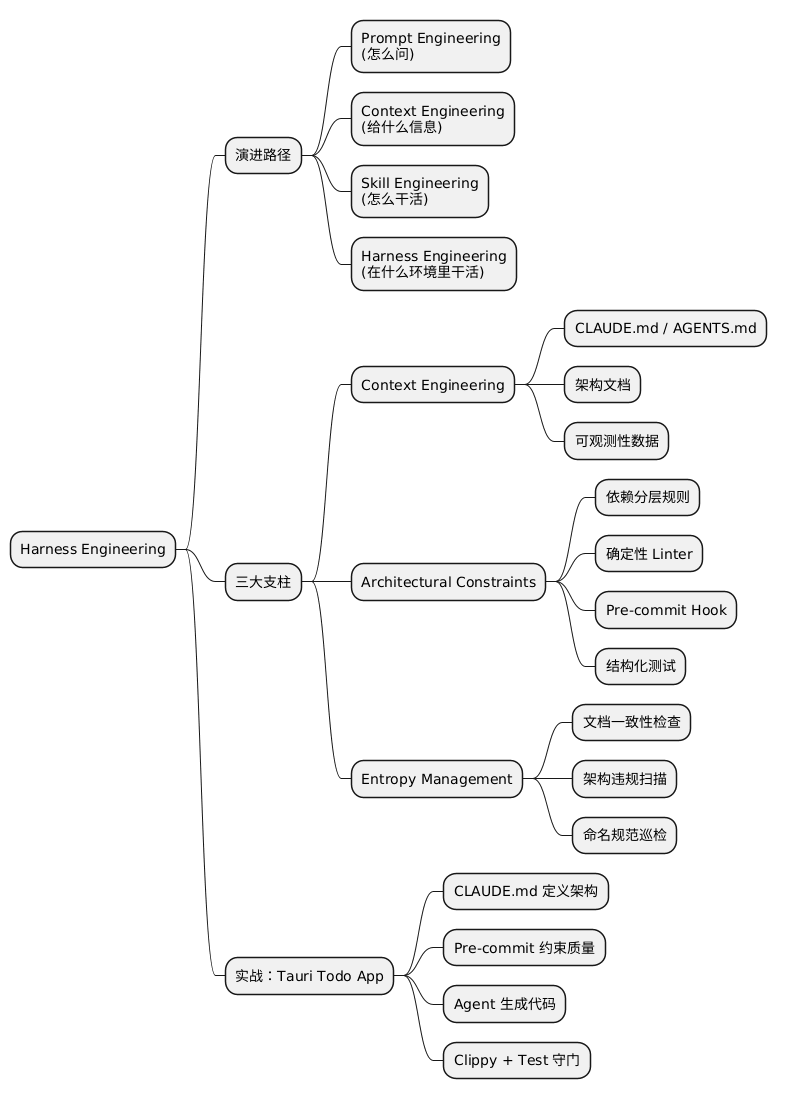
回头看这几年跟 AI 打交道的方式,经历了四次明显的进化。
第一阶段:Prompt Engineering(2022-2024)
一切从"怎么跟 AI 说话"开始。
那时候大家研究的是:怎么写 prompt 能让 ChatGPT 给出更好的回答?于是有了 few-shot、chain-of-thought、role-playing 等一堆技巧。本质上是一问一答——你精心设计一个问题,期望得到一个好回答。
打个比方,就像给人写邮件:主题怎么写、开头怎么措辞、关键需求怎么表达,都有讲究。可不管你邮件写得多漂亮,对方能做到什么程度,你控制不了。
第二阶段:Context Engineering(2025)
很快大家发现,光写好 prompt 不够。模型的回答质量,很大程度上取决于你给它的上下文信息够不够。
Andrej Karpathy 把这个趋势叫 Context Engineering——不只是写一个好问题,而是动态地把相关文档、对话历史、工具定义、RAG 检索结果等等一起塞进上下文窗口,让模型能"知道得更多"。
沿用邮件的比方:不光要把邮件正文写好,还要把所有相关附件、历史邮件、参考文档都挂上去,这样收件人才能做出靠谱的判断。
第三阶段:Skill Engineering(2025-2026)
Context Engineering 解决了"给模型看什么"的问题,可 AI Agent 真正干活的时候,光有上下文还不够——它还得知道怎么用工具。
Skill Engineering 的思路是:把 Agent 的能力拆成一个个可复用的 Skill(技能),每个 Skill 有明确的输入、输出、适用场景和执行步骤。Claude Code 的 Skill 体系就是这个思路的典型实践——你可以给 Agent 定义 /blog-write、/commit、/review-pr 这样的技能,每个技能背后是一套精确的指令、模板和工作流。
这比 Context Engineering 更进一步:不只是"给什么信息",还要"教会怎么做事"。
第四阶段:Harness Engineering(2026)
到了 Harness Engineering,视角又升了一层。它不再关注"怎么跟 Agent 对话"或者"给 Agent 什么信息",而是关注Agent 运行的整个环境。
OpenAI 的 Harness 包含三大支柱:
1. Context Engineering(上下文工程)
不只是把文档塞给 Agent,而是构建一整套"机器可读的知识库":
- 仓库内的
AGENTS.md/CLAUDE.md文件,编码项目规则和约定 - 架构文档、API 契约、风格指南——全部放在代码仓库里
- 可观测性数据(日志、指标、链路追踪)动态注入上下文
- CI/CD 流水线状态和测试结果实时反馈
核心原则:Agent 在上下文里看不到的东西,对它来说就不存在。所以代码仓库必须是 single source of truth,Slack 群里的讨论、Google Doc 里的决策,Agent 一概看不见。
2. Architectural Constraints(架构约束)
这是最反直觉的部分——约束 Agent 的解空间,反而提高了它的生产力。
OpenAI 团队的做法:
- 依赖分层规则:Types → Config → Repo → Service → Runtime → UI,每层只能导入左边的层
- 确定性 Linter:自定义规则,机械式检查,不靠模型判断
- LLM 审计 Agent:让 Agent 审查其他 Agent 写的代码
- 结构化测试:类似 ArchUnit 的架构合规验证
- Pre-commit Hook:提交前自动检查
为什么约束反而提效?因为没有约束的 Agent 会在无穷的解空间里浪费大量 token 走弯路。就像下棋,规则越清楚,棋手越能集中精力想战术。
3. Entropy Management(熵管理)
代码库像花园,不打理就会长草。OpenAI 专门跑一批"垃圾回收 Agent",定期巡检:
- 文档和代码是否一致?
- 有没有偷偷违反架构约束的代码溜进来?
- 依赖关系有没有产生环形引用?
- 命名规范有没有漂移?
这些 Agent 按计划定时运行,或者由事件触发,持续维护代码库的健康。
用一张表总结四次进化:
| 阶段 | 核心问题 | 比方 |
|---|---|---|
| Prompt Engineering | 怎么问? | 写一封好邮件 |
| Context Engineering | 给什么信息? | 把所有附件都挂上 |
| Skill Engineering | 怎么干活? | 给一份操作手册 |
| Harness Engineering | 在什么环境里干活? | 搭一条生产线 |
马具清单:不止 CLAUDE.md 一根缰绳
说到 Harness,很多人第一反应就是写一个 CLAUDE.md 或者 AGENTS.md。这当然重要,但只是马具里的一根缰绳。一匹马要跑得又快又稳,光有缰绳不够——还得有围栏、马鞍、马场和马夫。
缰绳:静态规则层
缰绳告诉 Agent"往哪跑",是最基础的约束。
CLAUDE.md / AGENTS.md 咱们已经聊了不少,它定义项目规则和架构约定。可光靠一个 Markdown 文件,Agent 有时候还是会"创造性发挥"。所以得配上机械式的硬约束:
Custom Linter Rules——比 CLAUDE.md 里写"请遵守编码规范"靠谱一万倍。CLAUDE.md 是建议,Linter 是法律。
# 自定义 ESLint 规则:禁止前端直接访问 localStorage(必须走 Tauri 后端)
# .eslintrc.js
module.exports = {
rules: {
'no-restricted-globals': ['error', 'localStorage', 'sessionStorage'],
}
};
# Rust clippy 配置:禁止 unwrap(),强制用 Result 处理错误
# clippy.toml
disallowed-methods = [
{ path = "core::result::Result::unwrap", reason = "Use ? or proper error handling" },
{ path = "core::option::Option::unwrap", reason = "Use ? or unwrap_or" },
]
Architectural Tests——验证代码结构本身是否合规。Java 生态有 ArchUnit,Rust 有 cargo-modules,TypeScript 可以用 dependency-cruiser:
// .dependency-cruiser.js 片段:前端不能直接 import 后端模块
module.exports = {
forbidden: [{
name: 'no-cross-boundary',
from: { path: '^src/components/' },
to: { path: '^src-tauri/' },
comment: 'Frontend components must not import Rust backend directly'
}]
};
Type System 和 Schema Validation——类型系统本身就是最优雅的马具。Rust 的所有权系统、TypeScript 的 strict mode、protobuf 的 schema 定义——这些在编译期就能拦住一大类错误,Agent 连犯错的机会都没有。
围栏:动态 Hook 层
缰绳管方向,围栏管边界。Agent 跑着跑着可能撞墙,围栏的作用是在它撞墙之前把它弹回来。
Pre-commit Hooks 前面已经提了,这是最常用的围栏。不过 Claude Code 还有一套更细粒度的 Hook 机制,可以在 Agent 的特定行为上触发检查:
// .claude/settings.json 中的 Hook 配置
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write",
"command": "cargo clippy --manifest-path src-tauri/Cargo.toml -- -D warnings 2>&1 | tail -5"
}
],
"PreCommit": [
{
"command": "cargo test --manifest-path src-tauri/Cargo.toml 2>&1 | tail -10"
}
]
}
}
这段配置的意思是:Agent 每次编辑或创建文件后,自动跑 cargo clippy;每次提交前,自动跑 cargo test。如果不通过,Agent 会看到错误信息并自动修复,不需要你盯着。
CI/CD Pipeline 是更远的围栏——即使本地 Hook 被绕过了(比如 --no-verify),GitHub Actions 或 GitLab CI 在合并前还会再检查一遍。建议至少配置:
- Lint 检查(clippy / eslint)
- 单元测试
- 构建是否通过
- 类型检查(tsc --noEmit)
马场:工具与权限层
马场决定了 Agent 的活动范围——它能用什么工具,能碰什么文件,能不能上网。
MCP Servers(Model Context Protocol)让你精确定义 Agent 可用的工具集。比如你可以给 Agent 一个"只读数据库 MCP",它能查数据但不能删库跑路:
// .claude/settings.json
{
"mcpServers": {
"sqlite-readonly": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-sqlite", "--readonly", "./data/todos.db"]
}
}
}
Skill 定义 把复杂操作标准化。与其让 Agent 自由发挥"帮我部署一下",不如定义一个 /deploy Skill,里面写清楚每一步该干什么、检查什么、回滚条件是什么。Agent 只能按 Skill 流程走,不能自作主张。
Sandbox / Container 是物理围墙。让 Agent 在 Docker 容器里跑,即使它写出了 rm -rf /,炸的也是容器不是你的宿主机。Tauri 开发时可以用 Dev Container:
// .devcontainer/devcontainer.json
{
"image": "rust:latest",
"features": {
"ghcr.io/devcontainers/features/node:1": {},
"ghcr.io/devcontainers/features/rust:1": {}
},
"mounts": [
"source=${localWorkspaceFolder},target=/workspace,type=bind"
]
}
马夫:熵管理巡检层
马场打扫不及时,到处是马粪,马也跑不快。OpenAI 专门设计了一批"垃圾回收 Agent"定期巡检,咱们也可以仿照这个思路:
文档一致性检查——README 说支持 5 个命令,实际代码里有 8 个?写个脚本定期对比:
#!/bin/bash
# scripts/doc-sync-check.sh
# 检查 README 中列出的 Tauri 命令是否与代码一致
readme_cmds=$(grep -oP '`\K[a-z_]+(?=`)' README.md | sort)
code_cmds=$(grep -oP '#\[tauri::command\]\s*pub fn \K[a-z_]+' src-tauri/src/commands/*.rs | sort)
diff <(echo "$readme_cmds") <(echo "$code_cmds") && echo "✅ Docs in sync" || echo "❌ Docs out of sync"
依赖健康检查——定期跑 cargo audit(Rust)和 npm audit(前端),发现有漏洞的依赖及时升级。可以挂在 CI 里每周跑一次,或者用 Dependabot / Renovate 自动提 PR。
Observability——监控 Agent 本身的行为。Token 用量突然飙升?错误率上去了?回退次数变多了?这些指标可以帮你判断 Harness 是不是需要调整。/cost 命令就是一个最简单的观测手段。
一句话总结
| 马具类型 | 作用 | 核心组件 |
|---|---|---|
| 缰绳(规则) | 告诉 Agent 往哪跑 | CLAUDE.md、Linter、架构测试、类型系统 |
| 围栏(Hook) | 跑偏了弹回来 | Pre-commit、Claude Hooks、CI/CD |
| 马场(工具) | 限定活动范围 | MCP Server、Skill、Sandbox、权限边界 |
| 马夫(巡检) | 定期打扫马厩 | 文档同步检查、依赖审计、行为监控 |
四样配齐,才算一套完整的 Harness。光有 CLAUDE.md 就上阵,相当于只给马套了根缰绳就去赛马——不翻车算运气好。
LangChain 的验证:模型没变,Harness 变了
OpenAI 的说法有没有实锤?LangChain 提供了一个很好的旁证。
他们的编码 Agent 在 Terminal Bench 2.0 上的成绩:
- 调整 Harness 之前:52.8%(排名 Top 30)
- 调整 Harness 之后:66.5%(排名 Top 5)
底层模型没换,只是改了 Harness——加了更好的约束规则、更精准的上下文管理、更完善的反馈回路。成绩直接跳了 14 个百分点,从中游冲到前五。
这说明什么?模型的能力天花板没变,但 Harness 决定了你能用出多少。
实战:不会 Rust,用 Harness Engineering 写一个 Tauri 桌面应用
理论讲完,来点实在的。完整代码已开源:github.com/walterfan/lazy-todo-app。
我是一个写了二十多年后端的老程序员,Java、C++、Python 都还行,可 Rust 基本没碰过。Tauri 是一个用 Rust + Web 前端技术构建桌面应用的框架,性能好、打包小、跨平台。我想用它写一个带优先级和倒计时的 Todo List 桌面应用,但我不会 Rust。
搁以前,我得先花几周学 Rust 的所有权、生命周期、借用检查器这些概念,再学 Tauri 的 API,然后才能动手。可现在有了 Harness Engineering 的思路,我不需要先成为 Rust 专家——我需要的是给 AI Agent 搭一个好 Harness,让它替我写 Rust,而我来把控方向和质量。
第一步:搭 Harness——写 CLAUDE.md
这是整个 Harness 的核心。在项目根目录创建 CLAUDE.md,把项目规则、架构约定、技术栈要求全部写清楚:
# CLAUDE.md - Tauri Todo App
## Project Overview
A cross-platform desktop Todo List app built with Tauri v2 + React + TypeScript.
Backend logic in Rust, frontend in React.
## Tech Stack
- Tauri v2 (latest stable)
- Rust (backend commands, state management, SQLite persistence)
- React 18 + TypeScript (frontend UI)
- SQLite via rusqlite (local data storage)
- TailwindCSS (styling)
## Architecture Rules
- All Tauri commands MUST be defined in `src-tauri/src/commands/` directory
- Each command module handles one domain (e.g., `todo.rs` for todo operations)
- State management uses Tauri's managed state (`tauri::State`)
- Frontend calls backend ONLY through `@tauri-apps/api/core.invoke()`
- NO direct filesystem access from frontend
- All data persistence goes through Rust/SQLite, never localStorage
## Code Style
- Rust: follow `cargo clippy` suggestions, use `Result<T, E>` for all fallible operations
- TypeScript: strict mode, no `any` types
- All Tauri commands must return `Result<T, String>` for proper error handling
- Use serde for all Rust ↔ Frontend data serialization
## File Structure
src-tauri/
src/
main.rs # Tauri app entry, register commands
commands/
mod.rs # Re-export all command modules
todo.rs # Todo CRUD commands
models/
mod.rs
todo.rs # Todo struct with Serialize/Deserialize
db.rs # SQLite connection and migrations
src/
App.tsx # Main React component
components/
TodoList.tsx # Todo list display
TodoItem.tsx # Single todo item
AddTodo.tsx # Add new todo form
hooks/
useTodos.ts # Custom hook wrapping Tauri invoke calls
types/
todo.ts # TypeScript types matching Rust structs
## Testing
- Rust: `cargo test` for backend logic
- Frontend: vitest for component tests
- Run `cargo clippy` before every commit
## Common Mistakes to Avoid
- Don't forget `#[tauri::command]` attribute on command functions
- Don't forget to register commands in `main.rs` via `.invoke_handler()`
- Always derive `Serialize, Deserialize` on structs passed to frontend
- Use `tauri::async_runtime` for async operations, not raw tokio
这份文件就是 Agent 的"操作手册"。注意几个关键点:
- 架构约束写死了:命令放哪个目录、状态怎么管理、前后端怎么通信,不给 Agent 自由发挥的空间
- 常见坑点列出来了:Tauri 新手容易忘的
#[tauri::command]、invoke_handler注册,提前告诉 Agent - 文件结构预定义了:Agent 不需要"设计"架构,按图施工就行
第二步:加约束——Pre-commit Hook 和 Linter
CLAUDE.md 写得再好,Agent 偶尔也会犯错。所以得加机械式的约束:
# 安装 pre-commit
pip install pre-commit
# 项目根目录创建 .pre-commit-config.yaml
cat > .pre-commit-config.yaml << 'EOF'
repos:
- repo: local
hooks:
- id: cargo-clippy
name: Rust Clippy
entry: cargo clippy --manifest-path src-tauri/Cargo.toml -- -D warnings
language: system
pass_filenames: false
types: [rust]
- id: cargo-test
name: Rust Tests
entry: cargo test --manifest-path src-tauri/Cargo.toml
language: system
pass_filenames: false
types: [rust]
- id: typescript-check
name: TypeScript Check
entry: npx tsc --noEmit
language: system
pass_filenames: false
types: [ts, tsx]
EOF
pre-commit install
这样每次 Agent 提交代码,cargo clippy 会检查 Rust 代码质量,cargo test 会跑测试,TypeScript 编译器会检查类型——任何一项不过,提交就被拦下来,Agent 会自动修复再重试。
第三步:开工——让 Agent 按 Harness 干活
Harness 搭好了,剩下的就是启动 Agent:
# 初始化 Tauri 项目
npm create tauri-app@latest todo-app -- --template react-ts
# 进入项目目录
cd todo-app
# 把 CLAUDE.md 放进去,然后启动 Claude Code
claude
# 给 Agent 第一个任务
> 请按照 CLAUDE.md 的架构规范,实现 Todo 的 CRUD 功能。
> 先实现 Rust 后端:数据模型、SQLite 存储、Tauri 命令。
> 然后实现 React 前端:列表展示、添加、完成切换、删除。
> 每完成一个模块先跑 cargo test 和 cargo clippy 确认通过。
因为 CLAUDE.md 把架构、文件结构、编码规范都定义好了,Agent 生成的代码大致是这样的:
Rust 后端——数据模型 (src-tauri/src/models/todo.rs):
use serde::{Deserialize, Serialize};
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct Todo {
pub id: i64,
pub title: String,
pub completed: bool,
pub created_at: String,
}
#[derive(Debug, Deserialize)]
pub struct CreateTodo {
pub title: String,
}
Rust 后端——Tauri 命令 (src-tauri/src/commands/todo.rs):
use tauri::State;
use crate::db::Database;
use crate::models::todo::{Todo, CreateTodo};
#[tauri::command]
pub fn list_todos(db: State<'_, Database>) -> Result<Vec<Todo>, String> {
db.list_todos().map_err(|e| e.to_string())
}
#[tauri::command]
pub fn add_todo(db: State<'_, Database>, input: CreateTodo) -> Result<Todo, String> {
db.add_todo(&input.title).map_err(|e| e.to_string())
}
#[tauri::command]
pub fn toggle_todo(db: State<'_, Database>, id: i64) -> Result<Todo, String> {
db.toggle_todo(id).map_err(|e| e.to_string())
}
#[tauri::command]
pub fn delete_todo(db: State<'_, Database>, id: i64) -> Result<(), String> {
db.delete_todo(id).map_err(|e| e.to_string())
}
前端——调用 Hook (src/hooks/useTodos.ts):
import { useState, useEffect, useCallback } from "react";
import { invoke } from "@tauri-apps/api/core";
import type { Todo } from "../types/todo";
export function useTodos() {
const [todos, setTodos] = useState<Todo[]>([]);
const refresh = useCallback(async () => {
const data = await invoke<Todo[]>("list_todos");
setTodos(data);
}, []);
useEffect(() => { refresh(); }, [refresh]);
const addTodo = async (title: string) => {
await invoke("add_todo", { input: { title } });
await refresh();
};
const toggleTodo = async (id: number) => {
await invoke("toggle_todo", { id });
await refresh();
};
const deleteTodo = async (id: number) => {
await invoke("delete_todo", { id });
await refresh();
};
return { todos, addTodo, toggleTodo, deleteTodo };
}
整个过程中我一行 Rust 都没写,但因为 Harness 定义了清晰的架构约束,Agent 生成的代码结构清晰、职责分明、错误处理规范。cargo clippy 和 cargo test 作为机械式守门员,确保代码质量不滑坡。
第四步:熵管理——持续维护
项目跑起来之后,还得防止代码库"长草"。可以在 CLAUDE.md 里加一节维护规则:
## Maintenance Rules
- Run `cargo clippy` and `cargo test` before every PR
- When adding a new command, ALWAYS update `main.rs` invoke_handler registration
- When adding a new Rust struct for frontend, ALWAYS add matching TypeScript type
- Keep README.md in sync with actual feature list
如果用 Claude Code 的 Hook 机制,还可以自动化这些检查——每次 Agent 修改 commands/ 目录下的文件时,自动检查 main.rs 里的命令注册是否更新了。
老程序员的体会
这次实验给我最大的感触是:Harness Engineering 降低了技术栈的切换成本,但没有降低工程思维的要求。
我不会 Rust,但我二十多年的工程经验告诉我:一个项目需要清晰的分层、明确的接口契约、可靠的质量门禁、持续的代码卫生。这些东西跟语言无关,跟框架无关,是软件工程的底层逻辑。
Harness Engineering 做的事情,本质上就是把这些工程经验编码化——从脑子里的"经验"变成仓库里的"规则",从口头上的"最佳实践"变成机器可执行的"约束"。Agent 负责写代码,我负责搭环境、定规则、把关质量。
这让我想起王阳明说的"知行合一"。以前咱们有很多工程经验(知),可落地执行(行)往往打折扣——Code Review 的时候放水、架构约定写在 Wiki 上没人看、测试覆盖率说好了 80% 最后变成 40%。现在 Harness 把"知"直接变成了"行":规则写在 CLAUDE.md 里 Agent 就得遵守,约束写在 Linter 里就不可能绕过,测试写在 Hook 里就不可能跳过。
当然,这事儿也有边界。Agent 生成的代码我不是完全不看——尤其是涉及安全、性能和核心业务逻辑的部分,还是得人工审查。Harness 管得住 Agent 的"手脚",管不住所有的"脑子"。
写在最后
从 Prompt Engineering 到 Harness Engineering,这条路走了不到四年。方向很清楚:人的角色从"写代码"变成了"设计环境"。
OpenAI 的实验证明了一件事:在足够好的 Harness 下,Agent 可以独立完成百万行代码的项目。LangChain 的实验证明了另一件事:同一个模型,换一个更好的 Harness,表现能跳一个量级。
对咱们做开发的人来说,这既是机遇也是挑战。机遇在于:你的工程经验——分层设计、质量门禁、架构治理——这些"老功夫"在 AI 时代不但没过时,反而成了搭 Harness 的核心竞争力。挑战在于:如果你的经验只停留在"某种语言怎么写"而不是"系统怎么设计",那确实会被 Agent 替代。
古人说,"善战者无赫赫之功"。最好的 Harness 工程师可能从来不写代码,可他搭出的环境让 Agent 写出的代码比大多数人工项目还靠谱。这听起来有点玄,不过 OpenAI 已经身体力行地证明了。
咱们这些老程序员,与其焦虑 AI 抢饭碗,不如赶紧琢磨怎么给 AI 搭一个好 Harness。毕竟,会骑马的人不会被马淘汰——前提是你手里有缰绳。
参考资料
- Harness Engineering: Leveraging Codex in an Agent-First World - OpenAI 原文
- Harness Engineering - Martin Fowler 的解读
- The Third Evolution: Why Harness Engineering Replaced Prompting in 2026 - Epsilla 的演进时间线
- The Rise of AI Harness Engineering - Cobus Greyling 的六大组件分析
- Tauri v2 Documentation - Tauri 官方文档
- lazy-todo-app - 本文实战案例源码
@startmindmap
* Harness Engineering
** 演进路径
*** Prompt Engineering\n(怎么问)
*** Context Engineering\n(给什么信息)
*** Skill Engineering\n(怎么干活)
*** Harness Engineering\n(在什么环境里干活)
** 三大支柱
*** Context Engineering
**** CLAUDE.md / AGENTS.md
**** 架构文档
**** 可观测性数据
*** Architectural Constraints
**** 依赖分层规则
**** 确定性 Linter
**** Pre-commit Hook
**** 结构化测试
*** Entropy Management
**** 文档一致性检查
**** 架构违规扫描
**** 命名规范巡检
** 实战:Tauri Todo App
*** CLAUDE.md 定义架构
*** Pre-commit 约束质量
*** Agent 生成代码
*** Clippy + Test 守门
@endmindmap