AI Friendly:为什么你的架构、API 和 UI 也该为 AI 设计?
Posted on Fri 13 March 2026 in Tech • 7 min read
| Abstract | AI Friendly:为什么你的架构、API 和 UI 也该为 AI 设计? |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Version | v1.0 |
| Updated | 2026-03-13 |
| License | CC-BY-NC-ND 4.0 |
简短大纲
展开看看
- **反直觉观点**:我们只关心 AI 怎么帮我们,却很少想过我们该怎么帮 AI - **双向赋能**:AI 赋能人(写代码、做决策、自动化),人赋能 AI(上下文、结构、规则) - **Context Engineering**:为什么"怎么跟 AI 说话"正在成为一门工程学科 - **AI Friendly 架构**:API、UI、文档、日志、配置——每一层的设计原则 - **路沿坡道效应**:AI Friendly 的设计往往对人也更友好 - **跨越鸿沟**:打通软件与软件、软件与人、人与人之间的三道裂缝 - **AI 时代程序员的转变**:从写代码的人变成定义规则的人 - **关于焦虑**:庄子的智慧——建立判断力、积累可迁移能力、找到生态位 - **实战清单 + 思维导图 + 扩展阅读**1. 反直觉:你在给 AI 打工,还是 AI 在给你打工?
美国前总统肯尼迪有一句名言:"不要问你的国家能为你做什么,要问你能为你的国家做什么。"
过去一年,每次有人跟我聊 AI,话题几乎总是:
"AI 能帮我做什么?"
能写代码、能做摘要、能分析数据、能生成测试用例——大家都在研究怎么让 AI 干更多的活。这没问题。但我越用 AI,越觉得这个问题只问对了一半。
另一半是:你能帮 AI 做什么?
这不是客气话。你给 AI 的输入质量,直接决定了 AI 给你的输出质量。同一个模型,给一句"帮我写个服务"和给一份详细的系统上下文 + 约束条件 + 示例代码,出来的东西天差地别。
我们花了 30 年让软件对人友好——User Friendly。按钮要大、反馈要快、流程要顺滑。现在,是时候认真想一想另一个方向了:怎么让我们的系统、架构、API、文档对 AI 也友好——AI Friendly。
这不是为了讨好 AI。是因为在人机协作的时代,你给 AI 的上下文越好,AI 回馈给你的价值就越大。 赋能从来不是单向的。
2. 双向赋能:不只是 AI 帮你
2.1 AI 赋能人:这部分大家已经很熟了
- 写代码:Copilot / Cursor / Claude Code,从自动补全到整个功能生成
- 做分析:丢一份日志进去,AI 帮你定位 root cause
- 写文档:API 文档、变更说明、复盘报告,AI 起稿效率极高
- 自动化:AI Agent 帮你执行部署、跑测试、发通知
这是 AI 给人的赋能。大家天天在用,不多说了。
2.2 人赋能 AI:这部分才刚开始
更值得关注的是反方向——人怎么赋能 AI。
我在前一篇文章里聊过 AI Skill 本质上是"给 AI 写的 SOP"。那只是冰山一角。人赋能 AI 的方式远比你想象的多:
| 赋能方式 | 具体手段 | 效果 |
|---|---|---|
| 提供上下文 | System Prompt、Project Rules、CLAUDE.md | AI 理解你的项目背景和约束 |
| 定义技能 | AI Skill / Cursor Rules / Custom Instructions | AI 按你的标准执行特定任务 |
| 结构化数据 | 良好的 API schema、typed response、OpenAPI spec | AI 能精确调用和解析你的系统 |
| 清晰文档 | 机器可读的文档、代码注释、README | AI 能自学你的代码库 |
| 可观测系统 | 结构化日志、metrics、trace | AI 能辅助诊断线上问题 |
| 标准化流程 | MOP/SOP → AI Skill | AI 能自动执行标准操作 |
你看出来了吗?"人赋能 AI"的核心手段,就是给 AI 提供高质量的上下文。 而这些上下文的质量,取决于你的系统设计、文档规范和工程实践。
换句话说:你的代码写得好不好、API 设计得规不规范、文档全不全,不再只影响人类同事的体验,还直接影响 AI 的表现。
3. Context Engineering:从 Prompt 到工程学科
3.1 Prompt Engineering 只是起点
2023 年大家都在聊 Prompt Engineering——怎么写 prompt 让 AI 给出更好的答案。但两年过去了,这个概念正在演化成一个更大的东西:Context Engineering(上下文工程)。
Prompt 只是你在对话框里输入的那几行字。但 Context 包括了 AI 能接触到的所有信息:
Context = System Prompt
+ Project Rules / CLAUDE.md / AGENTS.md
+ 当前文件和代码库结构
+ 打开的文件、光标位置
+ Git 状态、最近的 commit
+ Linter 错误、编译输出
+ MCP Server 提供的外部数据
+ AI Skill / Custom Instructions
+ 对话历史
+ ...
如果你用过 Cursor 或 Claude Code,你会发现它们做的事情,本质上就是在帮你构建更丰富的 Context——自动读取文件、自动获取 git 状态、自动加载 project rules。AI 的表现上限不取决于模型的能力,而取决于它拿到的 Context 的质量。
这跟你带一个新同事是一个道理。再聪明的人,如果你只给他一句话需求——"做个用户系统"——他做出来的东西大概率不是你想要的。但如果你给他详细的 PRD、系统架构图、代码规范、已有代码库的结构,他的产出质量会飞跃式提升。
3.2 Context 质量的四个维度
好的 Context 有四个特征:
1) 结构化(Structured)
❌ "这个服务有点问题,你看看"
✅ "service-user 在 us-east-1 的 P99 延迟从 200ms 跳到 2s,
开始时间 2026-03-13 09:15 UTC,影响 15% 的请求,
最近的变更是 commit abc123(加了新的 middleware)"
结构化的信息让 AI 能快速锁定问题范围,而不是在"有点问题"的模糊描述里猜来猜去。
2) 完整(Complete)
AI 不知道你没告诉它的东西。你以为"显而易见"的上下文——比如"我们用的是 PostgreSQL 15 而不是 MySQL"——对 AI 来说一点都不显而易见。
Context Engineering 的一个关键心法是:像给一个聪明但对你的项目一无所知的新人写工作交接一样,给 AI 写 Context。
3) 准确(Accurate)
过时的文档比没有文档更危险。如果你的 CLAUDE.md 写着"数据库用的是 MongoDB",但上个月已经迁移到了 PostgreSQL,AI 会基于错误的前提给你错误的建议。
4) 可发现(Discoverable)
好的 Context 不需要人手动塞给 AI。它应该放在 AI 能自动找到的地方:项目根目录的 README、标准位置的配置文件、代码里的类型注解和文档字符串。
4. AI Friendly 架构:逐层拆解
把"AI Friendly"这个概念落到具体的技术层面,每一层都有可以做的事。
4.1 API 层:让 AI 能调用、能理解
传统的 API 设计考虑的是"人类开发者能看懂"。AI Friendly 的 API 设计还要考虑"AI Agent 能自动发现、自动调用、自动解析"。
核心原则:
| 原则 | 说明 | 例子 |
|---|---|---|
| 强类型 | 所有入参出参有明确的类型定义 | OpenAPI 3.x schema,而不是 any |
| 自描述 | API 自身携带足够的元信息 | 带有 description 的 OpenAPI spec |
| 幂等 | 同一操作重复执行不会产生副作用 | PUT 而不是 POST 用于更新 |
| 一致性 | 命名、分页、错误码遵循统一规范 | 全局统一的 error response schema |
| 可发现 | 提供 schema endpoint 或文档 | /.well-known/openapi.json |
这些原则其实不新——它们就是"好的 API 设计"。但过去你可以不做(反正文档写得清楚,人类开发者能猜),现在不行了。因为 AI Agent 不会"猜",它需要精确的 schema。
一个实际场景:如果你的 AI Agent 要通过 MCP(Model Context Protocol)调用你的内部工具,它需要的是这样的接口描述:
{
"name": "deploy_service",
"description": "Deploy a service to the specified environment",
"parameters": {
"service_name": { "type": "string", "description": "Service identifier" },
"environment": { "type": "string", "enum": ["staging", "production"] },
"version": { "type": "string", "pattern": "^v\\d+\\.\\d+\\.\\d+$" }
},
"required": ["service_name", "environment", "version"]
}
每个参数有类型、有描述、有约束。AI 拿到这个定义就知道怎么调用,不需要读三页文档去推测。
4.2 UI 层:语义化不再是"加分项"
你可能觉得 AI 跟 UI 没什么关系——AI 又不看界面。但事实上,越来越多的 AI Agent 在通过浏览器跟 Web 应用交互(想想 browser-use 类的 Agent)。而你的前端代码写成什么样,直接决定了 AI 能不能"看懂"你的页面。
<!-- AI 不友好:一堆 div 套 div,没有语义 -->
<div class="c3x">
<div class="btn-like" onclick="doStuff()">
<div class="icon-wrapper"><svg>...</svg></div>
</div>
</div>
<!-- AI 友好:语义清晰,可被 AI 理解 -->
<form role="search" aria-label="Search users">
<label for="query">Search</label>
<input id="query" type="search" name="q" placeholder="Enter username" />
<button type="submit" aria-label="Submit search">Search</button>
</form>
AI 友好的 UI 有几个特征:
- 语义化 HTML:用
<nav>、<main>、<form>、<button>而不是万能<div> - ARIA 标签:
aria-label、role属性让 AI 理解每个元素的用途 - data 属性:
data-testid、data-action帮 AI(和测试框架)精确定位元素 - 可预测的交互模式:标准的表单提交、链接导航,而不是全部靠 JavaScript 黑魔法
你发现了吗?这就是无障碍设计(Accessibility)。 为视障用户做的无障碍优化,同时也让 AI 能更好地理解和操作你的界面。
4.3 文档层:从"给人看"到"人机共读"
过去写文档,你只要人能看懂就行。现在,你还要考虑 AI 能不能解析。
❌ 一份 50 页的 Word 文档,里面有大量截图和表格
→ 人能看但费劲,AI 基本没法用
✅ 一份结构化的 Markdown 文档,有清晰的标题层级、
代码块用 ``` 包裹、API 参数用表格列出
→ 人看着舒服,AI 也能精确提取信息
AI Friendly 的文档原则:
- 格式用 Markdown 或 reStructuredText——不要用 Word/PDF 作为主要格式
- 代码示例要可运行——不要给伪代码,给真实的、能跑的示例
- 参数说明用表格——而不是一段自然语言描述
- 版本号和更新日期——让 AI(和人)知道这份文档是否过时
- 放在代码仓库里——而不是放在某个 wiki 的角落里
一个实际的例子:Cursor 的 CLAUDE.md / .cursor/rules/ 机制,本质上就是"让你在代码仓库里放一份 AI 能自动读取的项目文档"。你写的越清楚,AI 对你项目的理解就越深。
4.4 可观测性层:结构化日志是金矿
当线上出了问题,你让 AI 帮你分析。AI 拿到的是什么?是日志。
❌ 非结构化日志
2026-03-13 09:15:23 ERROR something went wrong in user service
at com.example.UserService.getUser(UserService.java:42)
...一大坨 stack trace...
✅ 结构化日志
{
"timestamp": "2026-03-13T09:15:23Z",
"level": "ERROR",
"service": "user-service",
"method": "getUser",
"user_id": "u-12345",
"error": "ConnectionTimeout",
"duration_ms": 5023,
"trace_id": "abc-123-def"
}
结构化日志让 AI 能做到: - 按字段聚合分析("最近 1 小时有多少 ConnectionTimeout?") - 关联 trace("trace_id abc-123-def 经过了哪些服务?") - 趋势检测("duration_ms 是从什么时候开始上涨的?")
非结构化日志?AI 只能靠正则表达式去猜,而且经常猜错。
4.5 配置层:声明式优于命令式
这个原则在 DevOps 领域已经是共识了(想想 Terraform、Kubernetes YAML),但放到 AI 的语境下有了新的含义:
声明式配置是天然 AI 友好的。
# 声明式:描述"想要什么状态"
# AI 能直接读懂、修改、生成
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-service
spec:
replicas: 3
template:
spec:
containers:
- name: user-service
image: user-service:v2.1.0
resources:
limits:
memory: "512Mi"
cpu: "500m"
# 命令式:描述"怎么做到这个状态"
# AI 需要理解每一步的上下文和副作用
docker pull user-service:v2.1.0
docker stop user-service-1 user-service-2 user-service-3
docker run -d --name user-service-1 --memory 512m ...
docker run -d --name user-service-2 --memory 512m ...
docker run -d --name user-service-3 --memory 512m ...
声明式配置的好处:AI 可以直接生成、审查和修改,而不需要理解执行顺序和状态依赖。命令式脚本需要 AI 理解"当前状态"和"目标状态"之间的差异,复杂度高得多。
5. 路沿坡道效应:AI Friendly = Human Friendly
1945 年,美国开始在人行道边缘修建坡道(curb cuts),最初是为了方便轮椅使用者。后来人们发现,受益的远不止轮椅使用者——推婴儿车的、拉行李箱的、骑自行车的、送货的小推车……一个为少数人设计的无障碍特性,最终惠及了所有人。
这被称为"路沿坡道效应"(Curb Cut Effect)。
AI Friendly 的系统设计有同样的效应:
| AI Friendly 的设计 | 对 AI 的好处 | 对人的好处 |
|---|---|---|
| 强类型 API + OpenAPI spec | AI 能自动发现和调用 | 开发者自动生成 SDK 和文档 |
| 语义化 HTML + ARIA | AI Agent 能理解和操作页面 | 视障用户能使用屏幕阅读器 |
| 结构化日志 | AI 能自动分析和关联 | 人也能用 SQL 查询和聚合 |
| Markdown 文档在代码仓库中 | AI 能自动加载项目上下文 | 人能通过 git 追踪文档变更 |
| 声明式配置 | AI 能直接生成和审查 | 人能做 diff 和 code review |
| 清晰的错误信息 | AI 能理解失败原因并修复 | 开发者调试效率更高 |
你为 AI 做的每一项优化,同时也在让你的系统对人更友好。 这不是巧合——因为 AI Friendly 和 Human Friendly 的底层逻辑是一样的:清晰、结构化、可发现、无歧义。
好的设计本来就应该是这样的。AI 只是加速了"好设计"和"坏设计"之间的分化。
6. 人机协作的未来接口
6.1 CLI:最被低估的 AI 接口
在聊 MCP 之前,先说一个很多人忽略的事实:AI Agent 最顺手的"接口",其实是你已有的命令行工具。
你观察一下 Cursor 或 Claude Code 的工作方式——它们大量使用 Shell 来完成任务:git status、kubectl get pods、npm test、curl……AI 不需要什么花哨的协议,一个设计良好的 CLI 就够了。
为什么 CLI 天然 AI 友好?
-
文本输入,文本输出。CLI 的输入是结构化的命令字符串,输出是文本——这恰好是大语言模型最擅长处理的数据格式。不需要解析 DOM,不需要点击按钮,不需要处理 WebSocket。
-
自描述。一个好的 CLI 自带
--help,AI 读完就知道怎么用。参数有名字、有类型、有默认值——这比让 AI 去猜一个 Web 页面上的表单字段含义靠谱得多。 -
可组合。Unix 哲学里"小工具通过管道组合"的思想,在 AI 时代焕发了新生。AI 特别擅长把多个 CLI 命令串成一条管道来解决复杂问题——
kubectl get pods | grep Error | awk '{print $1}' | xargs kubectl describe,这种"即兴编排"正是 AI 的强项。 -
零额外开发成本。你的系统大概率已经有 CLI 了。把它暴露给 AI,不需要写一行新代码。
一个实际的例子:你有一个内部的部署脚本 deploy.sh:
# AI 可以直接调用
./deploy.sh --service user-service --env staging --version v2.1.0 --dry-run
# 输出是结构化的文本,AI 能直接解析
Dry run: deploying user-service v2.1.0 to staging
Current version: v2.0.9
Affected instances: 3
Estimated downtime: 0s (rolling update)
Rollback command: ./deploy.sh --service user-service --env staging --version v2.0.9
AI 读到这个输出就能判断:版本差异是 patch 级别、是滚动更新没有停机、回滚命令已经给出。不需要 MCP,不需要 SDK,一个 CLI 就够了。
所以第一条建议是:在追赶新协议之前,先检查你现有的 CLI 工具是否足够好用。 参数命名清晰吗?--help 信息完整吗?输出格式是结构化的吗?有没有 --json 选项?有没有 --dry-run?
这些改进对人类用户也同样有益——又是路沿坡道效应。
6.2 MCP:AI 的"USB 接口"
CLI 好用,但有局限:它依赖 Shell 环境,AI 需要有执行命令的权限,而且不同工具的输出格式不统一,AI 需要针对每个工具做适配。
当你需要更标准化、更安全、更可发现的方式让 AI 与系统交互时,MCP(Model Context Protocol) 就登场了。
MCP 做的事情很简单:给 AI Agent 提供一套标准化的方式来发现和调用外部工具。
你的内部系统
↓ 暴露为 MCP Server
↓ 提供 Tool / Resource / Prompt
↓
AI Agent (Claude / GPT / ...)
↓ 通过 MCP 协议调用
↓
执行操作、读取数据、返回结果
你可以把 MCP 理解为"AI 时代的 USB 接口"——不管你的系统用什么语言、什么框架,只要暴露一个符合 MCP 规范的接口,任何 AI Agent 都能接入。
CLI 和 MCP 的关系不是"二选一",而是"从轻到重"的光谱:
| 维度 | CLI | MCP |
|---|---|---|
| 接入成本 | 几乎为零(已有工具直接用) | 需要开发 MCP Server |
| 安全控制 | 依赖 Shell 权限 | 内建权限和 scope 管理 |
| 工具发现 | 靠 --help 和文档 |
Agent 自动发现可用 Tool |
| 输出格式 | 各工具不统一 | 统一的 JSON schema |
| 适用场景 | 开发/运维场景、单机操作 | 跨系统集成、生产级 Agent |
务实的路线是:先把 CLI 做好(立竿见影),再在高频、高价值的操作上包一层 MCP(长期投资)。 本质上,MCP Server 内部调用的往往也是 API 或系统接口——和 CLI 调用的是同一套东西,只是多了一层标准化的"外壳"。
这对架构的启示是:在设计内部工具和服务时,多想一步——这个功能未来能不能暴露为 CLI Tool 或 MCP Tool? 如果你的服务本身就有良好的 API 设计(强类型、自描述、幂等),加一层 CLI 或 MCP 几乎是零成本的事。
6.3 从 API First 到 AI First?
"API First" 是过去十年的设计理念——先设计 API,再实现功能。
我不想说"AI First"(这个词已经被滥用了),但有一个更务实的原则:
在设计任何接口时,问自己一个问题:如果调用方是一个 AI Agent 而不是一个人类开发者,这个接口够不够用?
- 如果你的部署工具只有一个 Web UI 没有 CLI 和 API?AI Agent 用不了。
- 如果你的监控系统只有仪表盘没有查询 API?AI Agent 看不到数据。
- 如果你的知识库只有全文搜索没有结构化查询?AI Agent 找不到精确答案。
这不是说要推翻现有设计。而是说在做新设计时,把"AI 能不能用"加入你的设计评审清单。
7. 一个真实的例子
让我用一个具体的场景来展示"AI Friendly"和"AI Unfriendly"系统的区别。
场景:线上服务延迟飙升,你想让 AI 帮你排查。
AI Unfriendly 的系统
你:"帮我看看 user-service 怎么了。"
AI:"好的,让我检查一下……
我没有找到这个服务的文档。
我无法访问日志系统(没有 API)。
我在代码库里找到了 UserService.java,但没有注释说明它依赖哪些下游服务。
monitoring dashboard 的 URL 是什么?(需要你手动截图给我看)
……
结论:信息不足,我只能猜。"
AI Friendly 的系统
你:"帮我看看 user-service 怎么了。"
AI:"好的,让我检查一下……
✅ 从 CLAUDE.md 读取到项目架构图,user-service 依赖 db-service 和 cache-service
✅ 通过 MCP 调用 metrics API,发现 P99 从 200ms 升到 3s(09:15 开始)
✅ 通过 MCP 查询结构化日志,发现大量 ConnectionTimeout 指向 db-service
✅ 查看 db-service 的 metrics,发现 CPU 使用率 95%
✅ 关联最近的变更记录,发现 09:10 有一次 db-service 部署(commit def456)
✅ 查看该 commit 的 diff,发现新增了一个没有索引的全表查询
结论:09:10 的 db-service 部署引入了一个缺少索引的 SQL 查询,
导致 CPU 飙升 → 连接池耗尽 → user-service 超时。
建议:回滚 db-service 到上一版本,然后给新查询加索引。"
区别在哪?不在于 AI 的能力——用的是同一个模型。 区别在于系统有没有给 AI 提供它需要的 Context:架构信息、可查询的 metrics API、结构化日志、关联的变更记录。
AI Friendly 不是让 AI 更聪明,是让聪明的 AI 能发挥出来。
8. 跨越鸿沟:填平三道裂缝
Geoffrey Moore 在《跨越鸿沟》(Crossing the Chasm)里讲的是技术产品从早期采用者到主流市场之间的那道裂缝。在 AI 时代,类似的鸿沟存在于三个层面——而"AI Friendly"要做的,恰恰就是填平这些裂缝。
8.1 软件与软件之间的鸿沟
现在大多数企业的内部系统长什么样?一堆"信息孤岛"。
部署系统是一个 Web 页面,监控系统是另一个仪表盘,日志系统在第三个平台,知识库在 Confluence,代码在 GitLab,需求在 Jira,沟通在 Slack……每个系统都有自己的登录方式、查询语言和数据格式。
人类可以忍受这种割裂——你的大脑充当了"集成中间件",在各个系统之间跳转、复制粘贴、人工关联信息。但 AI Agent 不行。它需要通过 API 来连接这些系统,而大多数内部工具根本没有可编程的接口。
填平这道鸿沟的方法:给每个关键系统暴露标准化的 API(前面讲的 MCP 就是干这个的)。不需要一次全做——先挑最高频的三个操作:部署、查日志、看监控。让 AI 能串起这三件事,已经能解决 80% 的问题了。
8.2 软件与人之间的鸿沟
这道鸿沟有两面。
一面是:软件怎么跟人沟通。 传统的软件通过 UI 展示信息,但 AI 时代多了一种方式——通过对话。你的系统能不能用自然语言"汇报"自己的状态?能不能让 AI 把复杂的监控数据翻译成人话?
另一面是:人怎么跟软件沟通。 过去是点按钮、填表单、写命令行。现在多了一种方式——通过 AI 做中介。你说"帮我把 user-service 回滚到昨天的版本",AI 翻译成具体的 kubectl 命令并执行。
但这两面都有一个前提:软件必须有足够的"自我表达能力"。如果你的系统连 API 都没有,AI 做不了翻译;如果你的日志只有一行 ERROR: something went wrong,AI 也翻译不出有用的信息。
8.3 人与人之间的鸿沟
这道可能是最容易被忽视的。
在一个团队里,隐性知识通常锁在少数几个人的脑子里——"这个服务为什么用了这个奇怪的配置?""那个接口为什么不能在下午三点调用?""上次上线出过什么事故?"新人来了只能靠口耳相传,关键人离职了知识就断档。
AI 在这里可以充当"知识的放大器":
- 把隐性知识写进 CLAUDE.md / Project Rules → AI 能随时回答新人的问题
- 把操作经验固化成 AI Skill → 标准做法不再依赖"老师傅带徒弟"
- 把复盘记录结构化 → AI 能在下次类似操作时主动提醒历史教训
人与人之间的鸿沟,本质上是知识传递的效率问题。 AI 不是替代面对面交流,而是让"一个人的经验"能以接近零成本传递给整个团队。
8.4 三道裂缝,同一个填法
你会发现,填平这三道裂缝的方法惊人地一致:
- 结构化——把非结构化的信息(口头经验、截图、Word 文档)变成结构化的数据(API、JSON、Markdown)
- 标准化——统一接口协议(MCP)、数据格式(OpenAPI)、文档规范(代码仓库内的文档)
- 自动化——让连接和传递不依赖人的手动操作
这不就是"AI Friendly 架构"在组织层面的投射吗?
9. AI 时代程序员的转变:从写代码到定义规则
9.1 AI 不是替代者,是放大器
每隔几个月就有一波"AI 要取代程序员"的讨论。我在这行干了二十多年,说实话,这种焦虑我理解但不太认同。
AI 确实在快速接管"写代码"这个动作。但"写代码"从来不是程序员最核心的价值——定义问题、设计架构、判断取舍才是。
打个比方:Excel 的出现没有消灭会计师,而是让会计师从"手工算数"里解放出来,专注于"财务分析和决策"。AI 对程序员做的是同样的事——把你从"把想法翻译成代码"的劳动中解放出来,让你专注于"想法本身"。
但这里有一个关键前提:你得真的有想法。
如果你的全部技能就是"把需求文档翻译成代码",那确实危险。但如果你能定义系统边界、设计容错机制、判断技术方案的长期影响、协调跨团队的技术决策——这些能力 AI 目前做不了,可预见的将来也做不了。
做"AI 友好架构"的意义在于:让你成为那个定义规则的人,而不是被规则定义的人。
9.2 从"点状工具"到"系统性编排"
坦白说,现在大多数人用 AI 还停留在"点状"阶段:
- 用 Copilot 补全几行代码
- 用 ChatGPT 问一个技术问题
- 用 Cursor 生成一个函数
这些都有用,但还远没有触及 AI 的真正杠杆点。
真正的杠杆在于:把 AI 能力编织进工作流、产品架构和协作流程里。
| 层次 | 举例 | 杠杆率 |
|---|---|---|
| 点状使用 | 用 AI 补全代码、回答问题 | 1.5x |
| 流程嵌入 | AI 自动 code review、自动生成测试、自动跑 SOP | 3-5x |
| 架构原生 | AI Agent 作为系统的一等公民,参与部署、监控、排障 | 10x+ |
从"用 AI 工具"到"设计 AI 能参与的系统",这是一个质变。不是每个人都需要走到第三层,但至少要意识到——谁能把 AI 能力编织进更大的系统里,谁就掌握了更大的杠杆。
9.3 四个值得探索的方向
如果你正在思考"我该往哪里使劲",这四个方向每一个都有长期的价值:
方向一:AI 原生架构设计
不是把 AI 当外挂,而是从设计之初就考虑 AI 的参与。Agent 友好的接口、可解释的系统输出、人机协作的容错机制(AI 操作出错时如何回滚和升级给人处理)。这篇文章讲的 AI Friendly 架构就属于这个方向。
方向二:工作流编排
识别哪些工作是"模式化的"(AI 能做),哪些是"创造性的"(人该做),然后设计人机混合的工作流。就像前面 MOP/SOP 文章里聊的"双层清单"——人负责决策,AI 负责执行。
方向三:知识工程
帮组织把隐性知识变成显性知识,让 AI 能理解业务上下文。写 CLAUDE.md、设计 AI Skill、构建 RAG 系统——这些都是知识工程。听上去不如"写一个炫酷的 AI 应用"那么性感,但它是让 AI 真正有用的基础设施。
方向四:人机交互创新
设计新的交互范式,让人和 AI 的协作更自然。不只是"聊天框"——可能是 AI 辅助的 code review 界面、AI 驱动的监控告警分诊、AI 参与的需求评审流程。这个方向需要同时理解技术和人的行为模式。
9.4 关于焦虑:庄子的智慧
最后说说焦虑这件事。
庄子说过:"吾生也有涯,而知也无涯。以有涯随无涯,殆已。"——用有限的生命去追逐无限的知识,那是要累死的。
这句话放到 AI 时代格外应景。每周都有新模型、新框架、新工具,Hacker News 上天天有人说"你该学这个了"。如果你试图追赶所有新技术,不但追不上,还会把自己搞得精疲力尽。
关键不是追赶,而是三件事:
第一,建立判断力。 知道什么值得学,什么可以先忽略。判断力来自对底层原理的理解——如果你懂操作系统、网络协议、分布式系统的基本原理,新技术再花哨也只是这些原理的排列组合。你不需要每个组合都学,但你需要能判断哪个组合跟你的工作相关。
第二,积累可迁移的能力。 具体的框架会过时,但有些能力不会: - 架构思维——如何拆解复杂问题、如何在约束下做决策 - 问题定义——把模糊的需求变成清晰的技术方案 - 沟通能力——让不同背景的人对齐理解 - 系统思考——理解局部优化和全局优化的关系
这些能力在 AI 时代不但不会贬值,反而会升值。因为 AI 越强,"定义问题"和"判断方案"的价值就越大——你不再需要亲手写每一行代码,但你需要知道该写什么、为什么写、怎么验证。
第三,找到你的生态位。 不要跟 AI 比写代码速度——你不可能赢。去做 AI 做不了的事:理解业务上下文、在模糊约束下做判断、跨团队协调资源、在压力下做出取舍、为技术决策承担责任。
一个不恰当但有效的类比:你不需要比挖掘机挖得快,你需要知道该在哪里挖。
10. 总结:你是放大器的放大器
五个要点回收:
-
赋能是双向的。我们习惯了让 AI 帮我们,但反过来,我们给 AI 提供的上下文质量——从项目文档到 API 设计到日志格式——直接决定了 AI 能回馈的价值。垃圾进,垃圾出。
-
AI Friendly 不是新发明。强类型 API、语义化 HTML、结构化日志、声明式配置、代码仓库里的文档——这些都是存在多年的"最佳实践"。AI 只是把"做不做这些事"的后果从"有点不方便"放大到了"根本没法用"。
-
路沿坡道效应。你为 AI 做的每一项优化,同时也在让系统对人更好用。这是一笔稳赚不赔的投资。
-
跨越鸿沟。软件与软件、软件与人、人与人之间的三道裂缝,用同一种方法填平:结构化、标准化、自动化。做 AI Friendly 架构不只是技术升级,是组织能力的升级。
-
AI 是放大器,你是放大器的放大器。AI 放大你的产出,而你的架构设计、知识工程、流程编排决定了这个放大器的倍率。与其焦虑"AI 会不会取代我",不如想想"我怎么把这个放大器的倍率从 2x 调到 10x"。
最后一个问题留给你:
如果你今天的全部工作突然被 AI 自动化了,你还剩下什么不可替代的东西?
答案不是"没有"。但如果你需要想很久才能回答,那可能是时候认真规划一下了。
行动清单
下周可以做的 7 件事:
系统层面: - [ ] 审视 API:你最重要的 3 个 API 有没有 OpenAPI spec?参数有没有类型和描述?试着让 AI 只看 spec 就调用一次 - [ ] 写 CLAUDE.md:在项目根目录加一份项目说明文件(不一定叫这个名字),包含架构概览、技术栈、核心约束、常见操作 - [ ] 升级日志:挑一个核心服务,把非结构化日志改成 JSON 格式,至少包含 timestamp / level / service / trace_id / message - [ ] MCP 试水:挑一个内部工具(比如部署系统、监控查询),尝试包一层 MCP Server,让 AI Agent 能调用
个人层面: - [ ] 盘点杠杆:列出你日常工作中最耗时的 5 件事,哪些是"模式化"的(可交给 AI),哪些是"判断性"的(你不可替代的价值) - [ ] 写一个 AI Skill:把你最熟悉的一个操作流程(部署/排障/review)写成 Skill 文件,让 AI 能按你的标准执行 - [ ] 想清楚生态位:花 30 分钟认真回答"如果 AI 接管了我的编码工作,我还能提供什么价值?"——写下来,不只是想想
思维导图
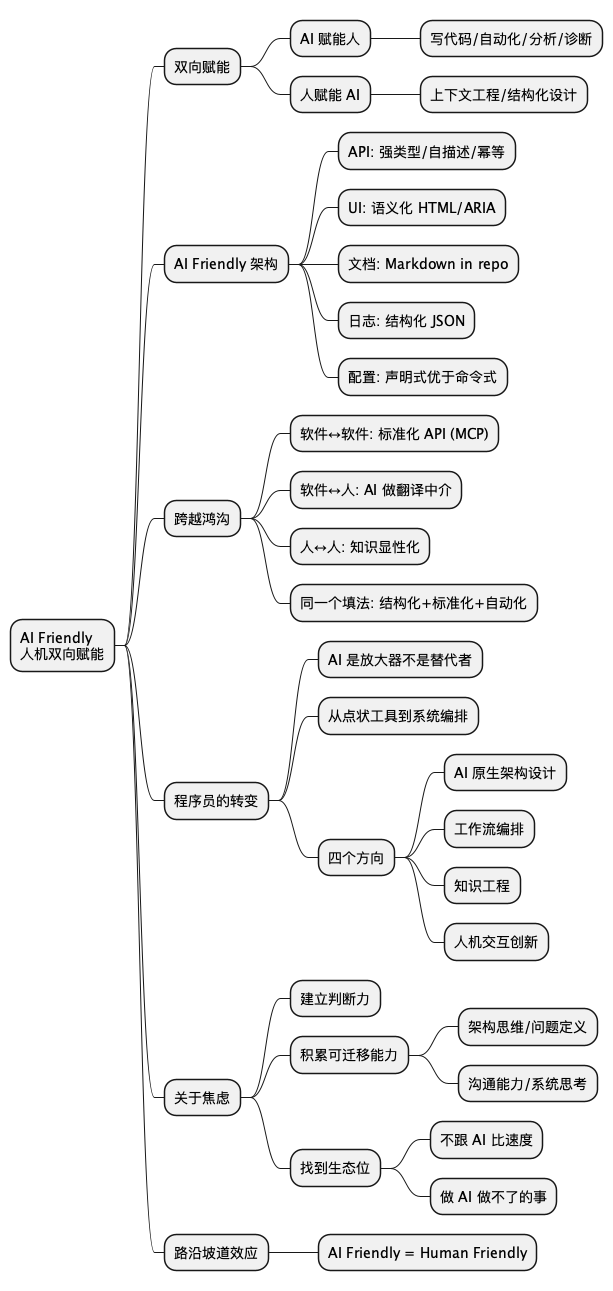
@startmindmap
* AI Friendly\n人机双向赋能
** 双向赋能
*** AI 赋能人
**** 写代码/自动化/分析/诊断
*** 人赋能 AI
**** 上下文工程/结构化设计
** AI Friendly 架构
*** API: 强类型/自描述/幂等
*** UI: 语义化 HTML/ARIA
*** 文档: Markdown in repo
*** 日志: 结构化 JSON
*** 配置: 声明式优于命令式
** 跨越鸿沟
*** 软件↔软件: 标准化 API (MCP)
*** 软件↔人: AI 做翻译中介
*** 人↔人: 知识显性化
*** 同一个填法: 结构化+标准化+自动化
** 程序员的转变
*** AI 是放大器不是替代者
*** 从点状工具到系统编排
*** 四个方向
**** AI 原生架构设计
**** 工作流编排
**** 知识工程
**** 人机交互创新
** 关于焦虑
*** 建立判断力
*** 积累可迁移能力
**** 架构思维/问题定义
**** 沟通能力/系统思考
*** 找到生态位
**** 不跟 AI 比速度
**** 做 AI 做不了的事
** 路沿坡道效应
*** AI Friendly = Human Friendly
@endmindmap
扩展阅读
- Geoffrey Moore, Crossing the Chasm — 技术产品跨越鸿沟的经典之作
- Anthropic, Model Context Protocol (MCP) — AI Agent 与外部系统交互的标准协议
- Cursor, Rules for AI — 如何通过 Rules 为 AI 提供项目上下文
- Google, API Design Guide — API 设计最佳实践
- W3C, WAI-ARIA Practices — Web 无障碍设计指南
- OpenAPI Initiative, OpenAPI Specification — API 描述标准
- 庄子,《养生主》 — "吾生也有涯,而知也无涯"
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。