用 pgvector 做 RAG:别急着上 Pinecone,你的 PostgreSQL 就够了
Posted on Tue 10 March 2026 in AI • 8 min read
| Abstract | 用 pgvector 做 RAG:别急着上 Pinecone,你的 PostgreSQL 就够了 |
|---|---|
| Authors | Walter Fan |
| Category | AI |
| Version | v1.0 |
| Updated | 2026-03-10 |
| License | CC-BY-NC-ND 4.0 |
短大纲
展开看看
- Hook: 你真的需要一个专门的向量数据库吗? - 什么是 RAG,以及为什么它需要向量搜索 - pgvector:给 PostgreSQL 装上"语义理解"能力 - Docker Compose 一键部署 pgvector + pgweb - Python 完整示例:CLI 工具,支持 index / query / chat / stats / reset - 代码拆解:自动探测维度、语义分块、兼容任意 OpenAI 兼容 API - 性能调优:索引策略与踩坑笔记 - 什么时候该用 pgvector,什么时候该换别的 - 总结 + CheckList + 思维导图你真的需要一个专门的向量数据库吗?
上周帮一个朋友 review 他的 RAG 架构,画出来大概长这样:用户提问 → 调 OpenAI embedding API → 发到 Pinecone 做相似度检索 → 拿回结果 → 再调 OpenAI 生成回答。五个步骤,三个外部服务,两张信用卡。
我问他:"你总共存了多少条向量?"
"大概……两万条。"
两万条。你知道这是什么概念吗?这连 PostgreSQL 热身都算不上。为了两万条向量专门搞一个 Pinecone,就好比为了烧一壶开水买了一台工业锅炉。
这篇文章想说服你的一件事:对于中小规模的 RAG 应用(百万级以下),pgvector + PostgreSQL 是性价比最高的方案。
你不用学新的查询语言,不用维护新的基础设施,不用担心数据一致性——因为你的向量和业务数据住在同一个数据库里,天然 ACID,天然 JOIN。
RAG 到底在干什么?一张图说清楚
RAG(Retrieval-Augmented Generation)的核心思路其实很朴素:LLM 不是什么都知道的,那就在它回答之前,先帮它翻翻资料。
@startuml
skinparam style strictuml
skinparam backgroundColor #FEFEFE
skinparam sequenceArrowColor #555555
actor User
participant "Application" as App
database "pgvector\n(PostgreSQL)" as PG
participant "Embedding\nModel" as Emb
participant "LLM" as LLM
User -> App: 提问
App -> Emb: 把问题转成向量
Emb --> App: question_embedding
App -> PG: SELECT * FROM docs\nORDER BY embedding <=> ?\nLIMIT 5
PG --> App: 最相关的 5 条文档
App -> LLM: 问题 + 相关文档\n(构建 prompt)
LLM --> App: 生成回答
App --> User: 回答
@enduml
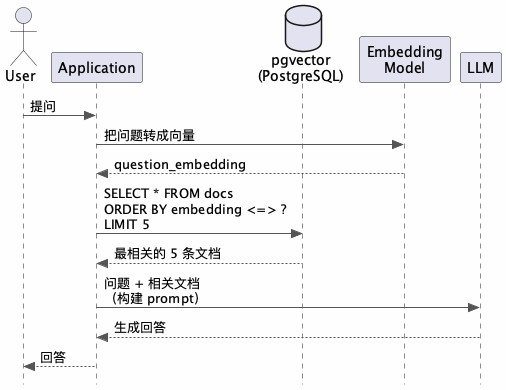
整个流程分两个阶段:
- 离线阶段(Indexing):把你的文档切块、算 embedding、存进 pgvector
- 在线阶段(Retrieval + Generation):用户提问 → 算问题的 embedding → 在 pgvector 里找最相似的文档块 → 拼成 prompt 喂给 LLM
关键洞察:RAG 的质量上限,取决于检索的质量,而不是 LLM 的能力。 你的 LLM 再聪明,如果检索回来的都是不相关的内容,它也只能一本正经地胡说八道。
pgvector:30 秒看懂它干了什么
pgvector 是 PostgreSQL 的一个扩展,它做了三件事:
- 新增
vector数据类型:你可以在表里加一列embedding vector(1536),就像加一个text或int字段一样自然 - 提供距离运算符:
<->欧氏距离、<=>余弦距离、<#>内积。写 SQL 就能做相似度搜索 - 支持 ANN 索引:IVFFlat 和 HNSW 两种近似最近邻索引,让百万级向量的搜索也能毫秒级返回
一句人话总结:pgvector 让 PostgreSQL 听懂了"语义"。
以前你只能 WHERE title LIKE '%机器学习%',现在你可以问"跟这个意思最像的文档有哪些"——哪怕文档里一个"机器学习"都没出现。
Docker Compose 一键部署
部署是最没技术含量但最容易翻车的环节。直接给你一份能跑的 docker-compose.yaml:
services:
pgvector:
image: ankane/pgvector
container_name: pgvector
environment:
POSTGRES_USER: ${DB_USER}
POSTGRES_PASSWORD: ${DB_PASS}
POSTGRES_DB: ${DB_NAME}
ports:
- "5432:5432"
volumes:
- pgvector-data:/var/lib/postgresql/data
networks:
- pgvector-net
restart: unless-stopped
pgweb:
image: sosedoff/pgweb
container_name: pgweb
ports:
- "8081:8081"
environment:
- PGWEB_DATABASE_URL=${DB_URL}
depends_on:
- pgvector
networks:
- pgvector-net
restart: unless-stopped
volumes:
pgvector-data:
networks:
pgvector-net:
driver: bridge
对应的 .env 文件:
DB_USER=rag_user
DB_PASS=rag_pass_2026
DB_NAME=rag_db
DB_URL=postgres://rag_user:rag_pass_2026@pgvector:5432/rag_db?sslmode=disable
启动:
docker compose up -d
几个注意点:
ankane/pgvector是 pgvector 官方维护的 Docker 镜像,自带 PostgreSQL + pgvector 扩展,开箱即用- pgweb 是一个轻量级的 PostgreSQL Web 管理工具,方便你直观地看数据。访问
http://localhost:8081就行 - 生产环境请务必改密码、限制端口暴露、配置 SSL
Python 完整示例:从 0 到 1 的 RAG
下面这个例子是完全可执行、可测试的。它不依赖 LangChain,只用最基础的库,让你看清每一步在干什么。而且它是一个带 CLI 的工具——支持索引 Markdown 文件、单次查询、交互式聊天和数据管理,不是那种跑一次就扔的 demo。
依赖安装
pip install psycopg2-binary openai httpx python-dotenv
用法速览
# 索引一个目录下的所有 Markdown 文件
python pgvector_rag_demo.py index ./docs/
# 单次 RAG 查询
python pgvector_rag_demo.py query "pgvector 怎么建索引?"
# 交互式聊天模式
python pgvector_rag_demo.py chat
# 查看知识库统计
python pgvector_rag_demo.py stats
# 清空所有索引数据(换模型后需要重建)
python pgvector_rag_demo.py reset
配置(.env 文件)
脚本从 .env 读取所有配置,embedding 和 LLM 可以用不同的服务——比如 embedding 用本地部署的模型,LLM 用云端 API:
# 数据库(二选一)
DATABASE_URL=postgresql://rag_user:rag_pass_2026@localhost:5432/rag_db
# 或者分开写:
# DB_HOST=localhost
# DB_PORT=5432
# DB_NAME=rag_db
# DB_USER=rag_user
# DB_PASS=rag_pass_2026
# Embedding 模型(兼容 OpenAI 接口的都行)
EMBEDDING_BASE_URL=https://api.openai.com/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL=text-embedding-3-small
# LLM(同样兼容 OpenAI 接口)
LLM_BASE_URL=https://api.openai.com/v1
LLM_API_KEY=sk-xxx
LLM_MODEL=gpt-4o-mini
一个值得注意的设计:embedding 和 LLM 的 base URL 是分开配置的。实际项目中你很可能 embedding 用便宜的本地模型,LLM 用云端大模型,这样成本最优。
完整代码
#!/usr/bin/env python3
"""
pgvector RAG Demo — Read markdown files, embed, store in PostgreSQL, then query.
Usage:
python pgvector_rag_demo.py index ./path/to/markdown/dir
python pgvector_rag_demo.py query "How does the RAG engine work?"
python pgvector_rag_demo.py chat
python pgvector_rag_demo.py stats
python pgvector_rag_demo.py reset
Prerequisites:
pip install psycopg2-binary openai httpx python-dotenv
"""
import os, sys, glob, textwrap
from pathlib import Path
from dotenv import load_dotenv
PROJECT_ROOT = Path(__file__).resolve().parent.parent
load_dotenv(PROJECT_ROOT / ".env")
load_dotenv(override=True)
# ============================================================
# Configuration
# ============================================================
def get_db_config() -> dict:
db_url = os.getenv("DATABASE_URL", "")
if db_url.startswith("postgresql"):
from urllib.parse import urlparse
p = urlparse(db_url)
return {
"host": p.hostname or "localhost",
"port": p.port or 5432,
"dbname": p.path.lstrip("/") or "rag_db",
"user": p.username or "postgres",
"password": p.password or "postgres",
}
return {
"host": os.getenv("DB_HOST", "localhost"),
"port": int(os.getenv("DB_PORT", "5432")),
"dbname": os.getenv("DB_NAME", "rag_db"),
"user": os.getenv("DB_USER", "postgres"),
"password": os.getenv("DB_PASS", "postgres"),
}
EMBEDDING_BASE_URL = (os.getenv("EMBEDDING_BASE_URL")
or os.getenv("LLM_BASE_URL", "https://api.openai.com/v1"))
EMBEDDING_API_KEY = (os.getenv("EMBEDDING_API_KEY")
or os.getenv("LLM_API_KEY", ""))
EMBEDDING_MODEL = (os.getenv("EMBEDDING_MODEL")
or os.getenv("LLM_EMBEDDING_MODEL", "text-embedding-3-small"))
LLM_BASE_URL = os.getenv("LLM_BASE_URL", "https://api.openai.com/v1")
LLM_API_KEY = os.getenv("LLM_API_KEY", "")
LLM_MODEL = os.getenv("LLM_MODEL", "gpt-4o-mini")
LLM_VERIFY_SSL = os.getenv("LLM_VERIFY_SSL", "true").lower() not in ("false", "0", "no")
TOP_K = 5
CHUNK_SIZE = 512
CHUNK_OVERLAP = 50
# ============================================================
# Embedding (OpenAI-compatible API)
# ============================================================
def get_embedding_client():
import httpx
from openai import OpenAI
http_client = httpx.Client(
headers={"X-Api-Key": EMBEDDING_API_KEY},
verify=LLM_VERIFY_SSL,
)
return OpenAI(
api_key=EMBEDDING_API_KEY,
base_url=EMBEDDING_BASE_URL,
http_client=http_client,
)
def get_embeddings(texts: list[str]) -> list[list[float]]:
client = get_embedding_client()
response = client.embeddings.create(input=texts, model=EMBEDDING_MODEL)
return [item.embedding for item in response.data]
def get_embedding(text: str) -> list[float]:
return get_embeddings([text])[0]
# ============================================================
# Text chunking (sentence-aware)
# ============================================================
def chunk_text(text: str, chunk_size: int = CHUNK_SIZE,
overlap: int = CHUNK_OVERLAP) -> list[str]:
"""按语义边界切块,带重叠窗口。"""
text = text.strip()
if not text:
return []
if len(text) <= chunk_size:
return [text]
chunks, start = [], 0
while start < len(text):
end = start + chunk_size
if end < len(text):
for sep in ["\n\n", "\n", ". ", "。", "! ", "? "]:
last_sep = text.rfind(sep, start + chunk_size // 2, end)
if last_sep != -1:
end = last_sep + len(sep)
break
chunk = text[start:end].strip()
if chunk:
chunks.append(chunk)
new_start = end - overlap
if new_start <= start:
new_start = end
start = new_start
return chunks
# ============================================================
# Markdown file reading
# ============================================================
def read_markdown_files(directory: str) -> list[dict]:
docs, seen = [], set()
for pattern in [os.path.join(directory, "*.md"),
os.path.join(directory, "**/*.md")]:
for filepath in glob.glob(pattern, recursive=True):
filepath = os.path.abspath(filepath)
if filepath in seen:
continue
seen.add(filepath)
try:
with open(filepath, "r", encoding="utf-8") as f:
content = f.read()
except Exception as e:
print(f" Skipping {filepath}: {e}")
continue
if not content.strip():
continue
title = Path(filepath).stem
for line in content.split("\n"):
line = line.strip()
if line.startswith("# "):
title = line.lstrip("# ").strip()
break
if line.startswith("Title:"):
title = line.split(":", 1)[1].strip()
break
docs.append({"title": title, "content": content, "source": filepath})
return docs
# ============================================================
# Database
# ============================================================
def get_connection():
import psycopg2
cfg = get_db_config()
conn = psycopg2.connect(**cfg)
print(f"Connected to PostgreSQL: {cfg['host']}:{cfg['port']}/{cfg['dbname']}")
return conn
def _detect_embedding_dim() -> int:
"""发一条短文本给 embedding 模型,自动探测输出维度。"""
try:
emb = get_embedding("dimension probe")
dim = len(emb)
print(f"Detected embedding dimension: {dim} (model: {EMBEDDING_MODEL})")
return dim
except Exception as e:
print(f"Could not probe dimension ({e}), defaulting to 1536")
return 1536
def init_db(conn):
dim = _detect_embedding_dim()
with conn.cursor() as cur:
cur.execute("CREATE EXTENSION IF NOT EXISTS vector;")
cur.execute("""
SELECT EXISTS (
SELECT 1 FROM information_schema.tables
WHERE table_name = 'rag_documents'
);
""")
if not cur.fetchone()[0]:
cur.execute(f"""
CREATE TABLE rag_documents (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
content TEXT NOT NULL,
source TEXT DEFAULT '',
chunk_index INTEGER DEFAULT 0,
embedding vector({dim}),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
""")
cur.execute(f"""
CREATE INDEX idx_rag_docs_embedding
ON rag_documents
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
""")
print(f"Created table rag_documents with vector({dim}) + HNSW index")
else:
cur.execute("""
SELECT atttypmod FROM pg_attribute
WHERE attrelid = 'rag_documents'::regclass
AND attname = 'embedding';
""")
row = cur.fetchone()
existing_dim = row[0] if row and row[0] > 0 else None
if existing_dim and existing_dim != dim:
print(f"Warning: existing column is vector({existing_dim}), "
f"but model produces {dim}-dim. Run 'reset' and re-index.")
print(f"Table rag_documents already exists (dim: {existing_dim or 'unset'})")
conn.commit()
def index_documents(conn, docs: list[dict]):
from psycopg2.extras import execute_values
total_chunks = 0
for doc in docs:
chunks = chunk_text(doc["content"])
if not chunks:
continue
print(f" {doc['title']}: {len(chunks)} chunks", end="")
batch_size = 64
all_embeddings = []
for i in range(0, len(chunks), batch_size):
all_embeddings.extend(get_embeddings(chunks[i:i + batch_size]))
print(".", end="", flush=True)
print()
rows = [(doc["title"], c, doc.get("source", ""), i, e)
for i, (c, e) in enumerate(zip(chunks, all_embeddings))]
with conn.cursor() as cur:
execute_values(
cur,
"""INSERT INTO rag_documents
(title, content, source, chunk_index, embedding)
VALUES %s""",
rows,
template="(%s, %s, %s, %s, %s::vector)",
)
conn.commit()
total_chunks += len(rows)
print(f"Indexed {total_chunks} chunks from {len(docs)} documents")
def search_similar(conn, query: str, top_k: int = TOP_K) -> list[dict]:
query_emb = get_embedding(query)
with conn.cursor() as cur:
cur.execute("""
SELECT id, title, content, source, chunk_index,
1 - (embedding <=> %s::vector) AS similarity
FROM rag_documents
ORDER BY embedding <=> %s::vector
LIMIT %s
""", (query_emb, query_emb, top_k))
columns = [desc[0] for desc in cur.description]
return [dict(zip(columns, row)) for row in cur.fetchall()]
def get_stats(conn) -> dict:
with conn.cursor() as cur:
cur.execute("SELECT COUNT(*) FROM rag_documents;")
total = cur.fetchone()[0]
cur.execute("SELECT COUNT(DISTINCT title) FROM rag_documents;")
docs = cur.fetchone()[0]
cur.execute("SELECT COUNT(DISTINCT source) FROM rag_documents;")
sources = cur.fetchone()[0]
return {"total_chunks": total, "documents": docs, "sources": sources}
# ============================================================
# RAG: Retrieve + Generate
# ============================================================
def rag_query(conn, question: str) -> str:
import httpx
from openai import OpenAI
results = search_similar(conn, question)
print(f"\nQuestion: {question}")
print(f"Retrieved {len(results)} chunks:")
for i, r in enumerate(results, 1):
print(f" [{i}] {r['title']} (chunk #{r['chunk_index']}, "
f"similarity: {r['similarity']:.4f})")
context_parts = []
for r in results:
snippet = r["content"][:500]
context_parts.append(f"### {r['title']}\n{snippet}\n(source: {r['source']})")
context = "\n\n".join(context_parts)
http_client = httpx.Client(
headers={"X-Api-Key": LLM_API_KEY}, verify=LLM_VERIFY_SSL,
)
client = OpenAI(
api_key=LLM_API_KEY, base_url=LLM_BASE_URL, http_client=http_client,
)
messages = [
{"role": "system", "content": (
"You are a knowledgeable assistant. Answer based on "
"the provided reference materials. If insufficient, say so. "
"Cite sources. Answer in the same language as the question."
)},
{"role": "user",
"content": f"Reference materials:\n{context}\n\nQuestion: {question}"},
]
response = client.chat.completions.create(
model=LLM_MODEL, messages=messages, temperature=0.3, max_tokens=1024,
)
answer = response.choices[0].message.content
print(f"\nAnswer:\n{textwrap.fill(answer, width=80)}")
return answer
# ============================================================
# CLI
# ============================================================
def main():
if len(sys.argv) < 2:
print("Usage: python pgvector_rag_demo.py <index|query|chat|stats|reset>")
sys.exit(1)
command = sys.argv[1]
conn = get_connection()
try:
init_db(conn)
if command == "index":
directory = sys.argv[2] if len(sys.argv) > 2 else "."
docs = read_markdown_files(directory)
if docs:
index_documents(conn, docs)
else:
print("No markdown files found.")
elif command == "query":
question = " ".join(sys.argv[2:])
rag_query(conn, question)
elif command == "chat":
print("Interactive RAG chat (type 'quit' to exit)\n")
while True:
try:
q = input("You: ").strip()
except (EOFError, KeyboardInterrupt):
break
if not q or q.lower() in ("quit", "exit", "q"):
break
rag_query(conn, q)
print()
elif command == "stats":
s = get_stats(conn)
print(f"Chunks: {s['total_chunks']}, "
f"Documents: {s['documents']}, Sources: {s['sources']}")
elif command == "reset":
with conn.cursor() as cur:
cur.execute("DROP TABLE IF EXISTS rag_documents;")
conn.commit()
print("All indexed data cleared. Run 'index' to re-index.")
finally:
conn.close()
if __name__ == "__main__":
main()
完整源码也在 lazy-rabbit-agent/example/pgvector_rag_demo.py。
代码拆解:几个值得细看的地方
自动探测 embedding 维度
以前的做法是硬编码 vector(1536),换个模型就得改代码。现在 _detect_embedding_dim() 会在初始化时发一条短文本给 embedding 模型,自动拿到输出维度。如果表已经存在且维度不匹配,还会给你一个明确的 warning:
def _detect_embedding_dim() -> int:
try:
emb = get_embedding("dimension probe")
return len(emb)
except Exception:
return 1536 # fallback
这个小细节在实际开发中省了不少麻烦——团队里总有人用不同的 embedding 模型,然后困惑地问"为什么插入报错"。
语义感知的文本分块
分块是 RAG 质量的生命线。机械地按固定字符数切,经常把一句话从中间劈开。这个版本的 chunk_text 会在指定范围内优先找语义边界(段落分隔符、句号、换行符)来断句:
def chunk_text(text, chunk_size=512, overlap=50):
# ...
for sep in ["\n\n", "\n", ". ", "。", "! ", "? "]:
last_sep = text.rfind(sep, start + chunk_size // 2, end)
if last_sep != -1:
end = last_sep + len(sep)
break
# ...
优先级:段落 > 换行 > 英文句号 > 中文句号。这样切出来的 chunk 语义更完整,检索质量自然更好。
兼容任何 OpenAI 兼容 API
不锁死 OpenAI。embedding 和 LLM 的 base URL、API key 都独立配置,任何兼容 OpenAI 接口的服务都能接:vLLM、Ollama、Azure OpenAI、各种国产大模型 API。这在企业环境里几乎是刚需——你不一定能直连 OpenAI。
HNSW 索引——为什么不用 IVFFlat?
CREATE INDEX idx_rag_docs_embedding
ON rag_documents
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
pgvector 提供两种 ANN 索引:
| IVFFlat | HNSW | |
|---|---|---|
| 原理 | 把向量分成若干簇,查询时只搜最近的几个簇 | 分层图结构,从顶层逐层逼近最近邻 |
| 建索引速度 | 快(需要先有数据) | 慢(但可以边插入边建) |
| 查询精度 | 取决于 probes 参数 |
取决于 ef_search 参数 |
| 适合场景 | 数据量大、批量导入后查询 | 持续有新数据写入、对精度要求高 |
我的建议:除非你有明确的理由用 IVFFlat(比如数据一次性导入且量级千万以上),否则默认用 HNSW。它更简单,增量写入友好,精度也更好。
HNSW 的两个关键参数:
- m(默认 16):每个节点的最大连接数。越大精度越高,但索引越大、建索引越慢
- ef_construction(默认 64):建索引时的搜索宽度。越大精度越高,建索引越慢
查询时还有一个运行时参数:
SET hnsw.ef_search = 100; -- 默认 40,越大越精确但越慢
距离运算符——选哪个?
<=>(余弦距离):最常用,适合文本 embedding。不受向量长度影响,只看方向<->(欧氏距离):适合已经归一化的向量,或者空间位置类的数据<#>(负内积):适合推荐系统中需要考虑向量长度("热度")的场景
99% 的 RAG 场景用 <=> 就对了。
分块策略——已经内置了
代码里的 chunk_text 已经实现了语义感知的切块:按段落和句子边界断句,带 50 字符的重叠窗口。这和 LangChain 的 RecursiveCharacterTextSplitter 思路一致,但不需要额外依赖。
如果你的文档格式更复杂(比如有代码块、表格),可能需要进一步定制分块逻辑——比如整个代码块不拆分,表格按行切而不是按字符切。
性能调优备忘录
跑通了是第一步,跑得好是另一回事。几个容易忽略的点:
1. 向量维度选择
| 模型 | 维度 | 适合场景 |
|---|---|---|
text-embedding-3-small |
1536 | 通用,精度好 |
text-embedding-3-large |
3072 | 精度更好,但存储和计算翻倍 |
all-MiniLM-L6-v2 |
384 | 本地部署,速度快 |
bge-small-zh-v1.5 |
512 | 中文专用,效果好 |
维度越高,精度通常越好,但存储和检索成本也线性增长。先用小维度验证效果,不够再换大的。
2. 批量操作
插入时一定要用批量 API,不要一条一条插。OpenAI 的 embedding API 支持一次传多条文本(上限 2048 条),网络开销差了几十倍。
3. 预热查询
HNSW 索引第一次查询会比较慢(需要加载到内存)。可以在服务启动后发一个 dummy 查询预热。
4. 监控索引大小
SELECT pg_size_pretty(pg_relation_size('idx_rag_docs_embedding'));
如果索引已经比你的内存大了,查询性能会断崖式下跌。这时候要么加内存,要么考虑分表。
pgvector vs. Elasticsearch vs. 专用向量数据库:怎么选?
我之前写过一篇 用 Elasticsearch 做 RAG 的文章,核心观点是"别只盯着向量数据库,ES 的混合检索才是扫地僧"。现在又写了 pgvector 这篇,难免有读者问:那我到底该用哪个?
先上对比表,再说判断逻辑:
| 考虑因素 | pgvector (PostgreSQL) | Elasticsearch | Pinecone / Milvus 等 |
|---|---|---|---|
| 检索能力 | 纯向量检索(余弦/欧氏/内积) | 混合检索(BM25 + Vector + RRF 融合) | 向量检索为主,部分支持混合 |
| 数据规模 | < 500 万条够用 | 千万级别没问题 | 千万到十亿级别 |
| 运维成本 | 复用现有 PG,几乎零成本 | 需要 JVM 调优、集群管理 | SaaS 免运维,但价格不透明 |
| 数据一致性 | ACID,天然和业务表 JOIN | 近实时(~1s 延迟) | 最终一致性 |
| 关键词精确匹配 | 需要自己加 WHERE / tsvector |
原生 BM25,开箱即用 | 弱,或不支持 |
| 字段加权 / 时间衰减 | 需要自己实现 | Function Score 原生支持 | 部分支持 |
| 结构化过滤 | SQL WHERE 子句,灵活 | bool query(must/should/filter) | 元数据过滤,能力有限 |
| 可视化监控 | pgweb 或 DBeaver | Kibana,功能强大 | 各家仪表盘 |
| 学习成本 | 会 SQL 就行 | ES DSL 有一定门槛 | 各家 SDK |
| 费用 | 几乎为零(自托管) | 自托管免费,Cloud 按量计费 | SaaS 按量,容易超支 |
我的判断逻辑
这三个方案不是互相替代的关系,而是不同阶段、不同场景的最优解:
选 pgvector 的场景: - 你已经有 PostgreSQL,不想引入新组件 - 数据量在百万级以下 - 检索场景以语义搜索为主,不需要复杂的关键词匹配 - 团队小,运维资源有限 - 需要向量数据和业务数据做 JOIN
选 Elasticsearch 的场景: - 用户的查询里经常包含精确关键词(错误码、订单号、专有名词) - 需要混合检索(BM25 + Vector),而且需要调权重、加时间衰减 - 数据需要按部门、角色、时间范围做结构化过滤 - 你需要 Kibana 来监控数据质量和检索效果 - 已经有 ES 集群在运行
选专用向量数据库的场景: - 数据量到了千万甚至亿级 - 需要多租户隔离、自动 sharding - 团队规模足够大,能承担额外运维成本
一句话总结:pgvector 是"穷人的向量数据库"(褒义),Elasticsearch 是"全能选手",Pinecone/Milvus 是"重型武器"。 先从 pgvector 开始跑通,检索质量不够再上 ES 的混合检索,数据量爆炸了再考虑专用方案。
踩坑笔记
几个我和同事实际踩过的坑,省得你再来一遍:
-
忘了
CREATE EXTENSION vector:连接数据库后第一件事就是执行这个,否则所有 vector 类型的操作都会报错 -
embedding 维度对不上:表定义的是
vector(1536),但你换了一个输出 384 维的模型。pg 会直接报错。示例代码里的_detect_embedding_dim()能自动探测并在维度不匹配时告警,但已有数据需要reset后重建 -
IVFFlat 索引要求先有数据:建 IVFFlat 索引前表不能为空,因为它需要先做聚类。HNSW 没这个限制
-
psycopg2不认识 vector 类型:查询结果里的 vector 列会返回字符串"[0.1, 0.2, ...]"。用pgvector这个 Python 包可以自动注册类型适配器 -
Docker 网络里的 hostname:在 docker-compose 里,服务间通信用服务名(如
pgvector)作为 hostname,但从宿主机连要用localhost
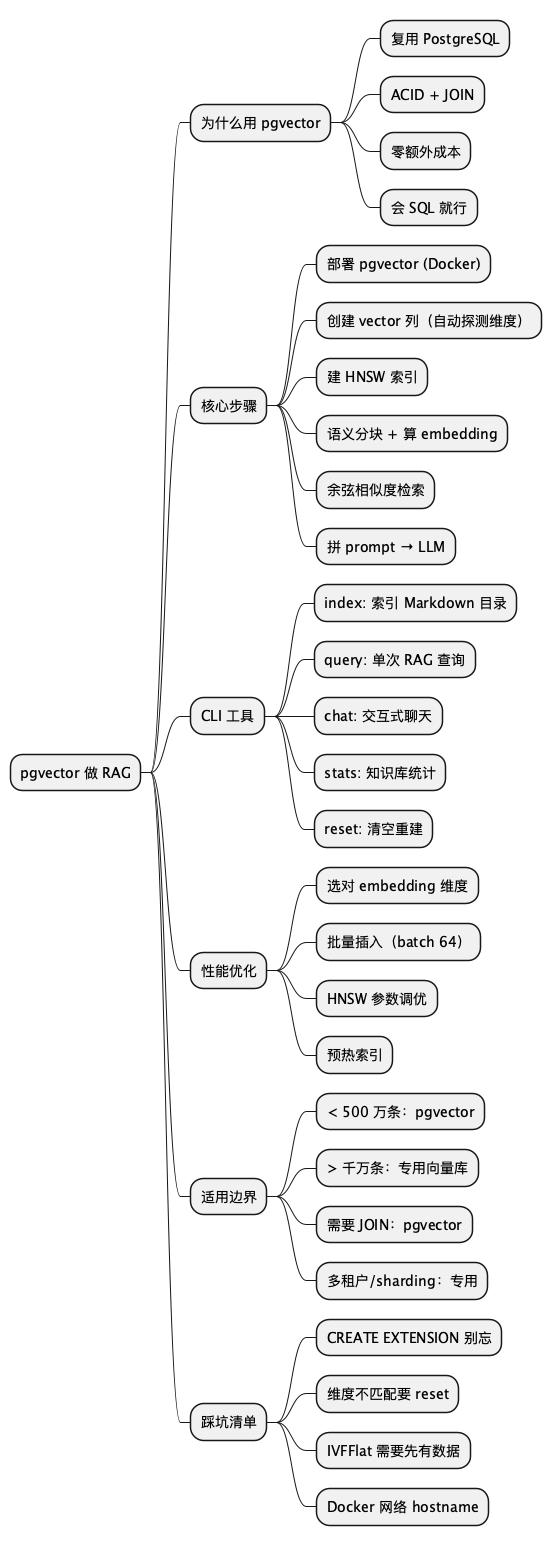
总结
@startmindmap
* pgvector 做 RAG
** 为什么用 pgvector
*** 复用 PostgreSQL
*** ACID + JOIN
*** 零额外成本
*** 会 SQL 就行
** 核心步骤
*** 部署 pgvector (Docker)
*** 创建 vector 列(自动探测维度)
*** 建 HNSW 索引
*** 语义分块 + 算 embedding
*** 余弦相似度检索
*** 拼 prompt → LLM
** CLI 工具
*** index: 索引 Markdown 目录
*** query: 单次 RAG 查询
*** chat: 交互式聊天
*** stats: 知识库统计
*** reset: 清空重建
** 性能优化
*** 选对 embedding 维度
*** 批量插入(batch 64)
*** HNSW 参数调优
*** 预热索引
** 适用边界
*** < 500 万条:pgvector
*** > 千万条:专用向量库
*** 需要 JOIN:pgvector
*** 多租户/sharding:专用
** 踩坑清单
*** CREATE EXTENSION 别忘
*** 维度不匹配要 reset
*** IVFFlat 需要先有数据
*** Docker 网络 hostname
@endmindmap
明天就能做的 CheckList
- [ ]
docker compose up -d启动 pgvector 和 pgweb - [ ] 配好
.env(数据库连接 + embedding/LLM API) - [ ]
python pgvector_rag_demo.py index ./your-docs/索引你的 Markdown 文档 - [ ]
python pgvector_rag_demo.py chat交互式验证检索效果 - [ ]
python pgvector_rag_demo.py stats确认索引数据量 - [ ] 用
EXPLAIN ANALYZE检查查询是否走了 HNSW 索引 - [ ] 如果要省钱,把
EMBEDDING_BASE_URL指向本地部署的模型服务
一个开放问题
当你的 RAG 系统检索到了相关文档,但 LLM 生成的回答仍然不对——你怎么诊断是检索的问题还是生成的问题?这个问题没有标准答案,但值得你认真想想。也许答案在于:先把检索和生成拆开来分别评估。
扩展阅读
- RAG 进阶指南:Elasticsearch 才是扫地僧 — 需要混合检索时的进阶方案
- pgvector GitHub — 官方仓库,README 就是最好的文档
- pgvector-python — Python 集成库,支持 SQLAlchemy / Django / psycopg
- ankane/pgvector Docker — 官方 Docker 镜像
- Supabase: pgvector vs Pinecone — 一份不错的对比测评
- HNSW 算法详解 — 如果你想深入理解索引原理
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。