使用第一性原理做架构设计
Posted on Tue 13 January 2026 in Journal
| Abstract | 使用第一性原理做架构设计 |
|---|---|
| Authors | Walter Fan |
| Category | learning note |
| Status | v1.0 |
| Updated | 2026-01-13 |
| License | CC-BY-NC-ND 4.0 |
你有没有这种“架构既视感”——哦不,应该叫“时空穿越感”:
开会时大家讨论得热火朝天,最后落地成一句话:“我们先上 Kubernetes + 微服务 + MQ + Redis + ES,后面再优化。”
听起来很像“先把厨房装修成米其林后厨,再学做蛋炒饭”。问题是:蛋炒饭到底要不要这么复杂?
第一性原理(First Principles)不是用来装腔作势的,它的实用价值只有一句:
把“习惯/经验/潮流”从决策里请出去,让“目标/约束/不变量”坐到主位。
TL;DR(先把结论给你)
第一性原理做架构,其实就 5 步
- Step 1:把问题拆到“物理层”:用户到底要什么?系统必须保证什么?(先别急着选技术栈)
- Step 2:写出 3 个“不变量”:无论怎么演进,都不能破的底线(安全、合规、一致性、可用性……)
- Step 3:列清 5 个“硬约束”:钱、时间、人、合规、上下游(别拿 PPT 对抗现实)
- Step 4:从不变量推导结构:把职责分出来,把边界画出来,把失败路径想清楚
- Step 5:做“可解释的取舍”:你牺牲了什么、换来了什么、未来怎么回滚/怎么演进
评审会自查清单(收藏版)
- 目标是否可量化:SLO/延迟/成本上限有没有数字?还是“要快、要稳、要省”这种玄学
- 边界是否清楚:哪些属于同一事务/同一一致性域?哪些是“最终一致即可”
- 失败路径是否设计:超时、重试、降级、限流、熔断、隔离、回滚有没有写
- 可观测性是否内建:日志/指标/追踪/成本与配额是不是一等公民
- 演进路线是否明确:MVP 怎么活下去?后续如何拆/如何扩/如何迁移
0. 先把两个词讲清楚:第一性原理是什么?架构设计是什么?
我见过不少“架构讨论会”,开场 10 分钟就开始互扔名词:微服务、DDD、K8s、Service Mesh、CQRS……
听着像在点奶茶:“全糖 + 去冰 + 加珍珠 + 加椰果 + 加布丁 + 再来一份集群。”
但架构设计这件事,最怕的不是你不会点单,而是你压根没问:你到底渴不渴?
0.1 什么是第一性原理(First Principles)?
一句话版:把“别人这么干”暂时放一边,从目标、约束、和不变量出发,自己推导答案。
工程里它更像一种“反射动作”: - 遇到新需求,先问:用户真正的痛点是什么? - 遇到架构争论,先问:我们到底在优化哪个指标? - 遇到技术选型,先问:不选它会死吗?选它会不会把未来锁死?
你会发现,很多“架构讨论”其实是“词汇量竞赛”。第一性原理负责把竞赛掐掉,让大家回到同一个起跑线:事实、约束、推导。
它的反面也不是“经验”,而是未经检验的类比:
别人这么做、业内这么做、某大厂这么做——于是我们也这么做。
把它落到纸面上,就是三件事: - 目标(Goal):到底要优化什么?延迟、吞吐、可用性、成本、交付速度? - 约束(Constraints):钱、人、时间、合规、上下游(别拿 PPT 对抗现实) - 不变量(Invariants):无论怎么演进都不能破的底线(钱不能错、数据不能丢、权限不能绕过……)
0.2 什么是架构设计(Architecture Design)?
一句话版:为了达成目标、在约束下守住不变量,你做的一组“关键决策”。
注意这句话里最重要的不是“架构”,而是“关键决策”。架构设计通常包含: - 系统边界:哪些必须强一致?哪些可以最终一致? - 职责拆分:模块/服务怎么分?接口契约是什么? - 数据归属:谁写谁读?如何同步?如何对账? - 部署与隔离:爆炸半径怎么控?热点怎么扩?依赖怎么隔离? - 失败策略:超时、重试、降级、限流、熔断、幂等、补偿怎么做? - 可观测性:日志/指标/追踪/审计/成本是否一等公民?
换句话说:架构设计不是“选择技术栈”,而是“决定系统如何活下去”。
1. 架构设计里最常见的“伪问题”
1.1 “我们要不要微服务?”
这是个典型伪问题。真正的问题是: - 你要不要独立发布?(组织结构与交付节奏) - 你要不要隔离故障?(爆炸半径) - 你要不要独立扩缩容?(成本与热点)
微服务只是其中一种答案,且代价很硬:治理、调用链、灰度、版本兼容、分布式一致性……你要么为它付钱,要么让事故替你付钱。
1.2 “我们要不要上 MQ?”
更本质的问题通常是: - 你是不是需要削峰填谷? - 你是不是需要异步化来换延迟/吞吐? - 你是不是要解耦发布(生产者/消费者独立演进)?
如果你的真实需求只是“把慢操作放后台”,一个任务队列就够了;你上了全家桶,只是把“慢”升级成了“慢且难排查”。
2. 第一性原理的“架构推导模板”(可直接抄)
下面这套我很爱用,像写作文提纲一样,能把“散装观点”变成“可评审的结论”。
2.1 读者画像(Who)+ 场景(When/Where)
用 2-3 句话说清楚: - 谁在什么场景下用?频率多高?峰值多高? - 失败的代价是什么?(钱/声誉/合规/体验)
2.2 目标(Goal)——写成可以打分的
建议至少列: - SLO:可用性、P95/P99 延迟、吞吐 - 成本上限:月度预算/单请求成本上限 - 交付窗口:MVP 什么时候必须上线
例如(随便写个“能打分”的版本): - 可用性 ( \ge 99.9\% ) - P95 延迟 ( \le 200ms )(核心接口) - 日活 10 万,峰值 2k QPS - 3 周内交付 MVP
2.3 不变量(Invariants)——架构的“地心引力”
我通常会要求团队写出至少 3 条(少了说明没想明白): - 合规不变量:PII/权限/审计不可绕过 - 一致性不变量:哪些数据必须强一致?一致性的边界在哪? - 可用性不变量:哪些能力必须在部分依赖挂掉时仍可用(降级)
2.4 约束(Constraints)——把现实写在纸面上
典型 5 类: - 人:团队规模/技能栈(“我们只有 2 个后端”这句话非常重要) - 钱:预算与资源 - 时间:上线窗口 - 环境:机房/云、网络边界、依赖系统 - 组织:跨团队协作成本、审批流程
2.5 推导(Derivation)——从不变量推出结构,而不是从技术推出结构
这一步是核心:
边界 = 不变量的边界。
例如:强一致的部分放在同一事务域;最终一致的部分允许异步化。
你可以用这张“架构推导表”做评审材料:
不变量/约束 -> 设计选择 -> 代价/风险 -> 缓解手段
---------------------------------------------------
隐私合规必须可审计 -> 统一鉴权与审计层 -> 增加链路开销 -> 异步落审计+采样
核心数据强一致 -> 单写主库+事务边界 -> 扩展性受限 -> 读写分离/分库分表路线图
3周交付MVP -> 先单体模块化 -> 未来拆分成本 -> 明确模块边界+接口契约
3. 一个更贴近 SaaS 的案例:SDK/Client Version 治理(别让旧版本把你拖进“维护地狱”)
如果你做的是 SaaS 服务,而且对外提供各种 SDK/Client(Web、iOS、Android、Desktop、Server SDK……),你大概率见过这种“人间真实”: - 你发布了新能力,文档写得像诗,但线上报错像雨:“为啥只有某些客户一直 4xx/5xx?” - 你修了一个安全漏洞,公告发了三轮,结果发现:漏洞还在,因为一堆客户端根本没升级 - 你想下线一个废弃接口,会议开完一圈,最后结论是:“先别动,怕炸。”(翻译:继续背锅)
这就是典型的“版本治理失败”。而版本治理这种问题,特别适合用第一性原理:
因为它不是技术难,而是系统性约束 + 组织现实叠加出来的。
3.1 先把场景写清楚:你治理的不是版本号,是“真实世界的惯性”
- 你是 SaaS:多租户、长尾客户、集成方式五花八门
- 客户端形态多:Browser、Mobile、Desktop、Server-to-Server
- 升级阻力大:客户的发布节奏、审批流程、灰度策略、甚至“负责人离职了”
真正的问题不是“版本太多”,而是: - 你无法知道谁在用什么版本 - 你无法控制谁必须升级 - 你无法在不炸客户的前提下演进协议与能力
3.2 目标(Goal)与不变量(Invariants)
先把“地心引力”写出来,后面才推得动。
目标(可打分)(示例):
- 版本可见:任意一次请求,都能知道 client_type / sdk_version / capability_set / tenant
- 风险可控:支持“按租户/按版本”灰度、降级、封禁、强制升级
- 演进可持续:能在 6-12 个月内完成一次大版本演进,而不是永远兼容到宇宙尽头
- 成本可控:兼容层的复杂度可度量、可逐步削减(而不是越修越像意大利面)
不变量(底线)(建议至少 3 条): - 安全不变量:高危漏洞版本必须可快速阻断(Kill Switch),不能靠“发公告求升级” - 合规/审计不变量:版本治理动作必须可审计(谁对哪个租户做了什么策略) - 兼容性不变量:服务端永远要“说人话”——对不支持的能力给出明确错误码与升级指引,而不是让客户猜
3.3 约束(Constraints):这事 90% 不是技术问题,是现实问题
- 客户升级不可控:你不能指望客户“马上升级”,尤其是企业客户
- SDK 发布渠道不同:App Store、企业内部分发、浏览器缓存、包管理器……
- 多语言/多平台:你做不了“一刀切”,但你可以做“统一策略”
- 研发资源有限:治理必须先做“最小闭环”,别一上来就搞成平台化大工程
3.4 从不变量推导边界:协议/能力/版本,谁才是“真相”?
这里有一个关键认知:版本号不等于能力。
同一个 sdk_version=1.2.3,可能因为:
- 产物被二次打包
- Feature Flag 默认值不同
- 部分能力需要额外配置
导致“看起来同版本,实际行为不一样”。
所以治理的“真相”应该是: - 版本(Version):用于粗粒度分组与发布 - 能力集(Capabilities):用于精确决策(支持哪些 API/字段/编解码/鉴权方式) - 策略(Policy):用于控制与治理(允许/警告/降级/封禁/强制升级)
3.5 推导结构:一套可落地的 SDK/Client Version 治理架构
下面这个结构不花哨,但很能打,核心思想是:先把“识别 + 决策 + 执行”闭环做起来。
3.5.1 Version/Capability Discovery(识别层:先看得见)
每个 SDK/Client 请求必须携带“可观测的身份”:
- X-Client-Type:ios/android/web/desktop/server
- X-SDK-Version:语义化版本或 build id
- X-Capabilities:能力列表(或能力 hash)
- X-Tenant-Id:租户(SaaS 的灵魂字段)
服务端要做的事情非常朴素:把这些字段变成一等公民(日志、指标、追踪维度)。
3.5.2 Version Registry(版本目录:把“版本事实”集中管理)
做一个“版本目录”(可以是服务,也可以是配置中心+管理界面):
- 版本元数据:发布时间、支持平台、依赖版本、已知问题、安全状态
- 状态机:ACTIVE / DEPRECATED / EOL
- 映射:sdk_version -> capability_set(重要:允许同版本多能力集)
别小看这个目录:它是你后面所有治理动作的“事实来源”。
3.5.3 Policy Engine(策略引擎:把治理规则写下来)
策略引擎的输入通常是: - tenant + client_type + sdk_version + capabilities + endpoint
输出是一个“决策”: - allow:正常放行 - warn:放行但返回升级提示(header/response) - degrade:降级到兼容模式(例如关闭某能力) - block:直接拒绝(安全漏洞、EOL 强制) - force_upgrade:返回明确错误码 + upgrade URL(或最小版本要求)
策略的优先级建议这样设计:
1) 安全封禁(最高)
2) 租户特例(VIP/特批)
3) 全局最小版本线(min supported version)
4) 渐进式弃用(deprecation schedule)
5) 默认策略
3.5.4 Compatibility Layer(兼容层:把“不可控的过去”关进笼子)
现实是:你一定会遇到旧版本还在用。兼容层要做两件事: - 协议兼容:字段缺失、字段语义变化、旧鉴权方式 - 行为兼容:旧流程依赖的“历史 bug”(是的,有些 bug 也是契约)
但兼容层必须有“寿命”:
每一条兼容逻辑都要在 Version Registry 里绑定一个“到期日/替代方案/影响租户列表”,否则它会变成永久债务。
3.5.5 Upgrade Experience(升级体验:别让客户升级像渡劫)
你可以强制升级,但你更应该让升级“可操作”:
- 返回明确错误码(例如 SDK_VERSION_TOO_OLD)
- 提供升级指引链接(文档、SDK 下载、迁移指南)
- 关键变更提供“迁移期”:warn -> degrade -> block 的三段式节奏
3.6 失败路径设计:版本治理的“事故现场”都在这里
3.6.1 旧版本触发安全漏洞(必须能一键止血)
你需要的是 Kill Switch,而不是“紧急发邮件”:
- 按 sdk_version 或 build_id 封禁
- 按租户封禁(某客户被攻击时快速隔离)
- 按能力封禁(某 feature 有漏洞,先关再修)
3.6.2 版本看起来没问题,但能力不匹配(最难排查的那种)
把“能力协商”做成协议的一部分:
- 客户端启动时拉一次 capability_profile
- 每次请求带 capability_hash
- 服务端按 hash 决策并落审计
这样你排查问题就不靠玄学了:
“你这台客户端到底支不支持 X?”——日志里一眼就能看到。
3.6.3 EOL 版本还在跑,怎么办?
别一刀切,按节奏: - 第 1 阶段:warn(提示 + 埋点统计) - 第 2 阶段:degrade(限制部分高风险能力) - 第 3 阶段:block(明确错误码 + 升级路径)
同时提供“租户特批”机制:
允许某些大客户延长,但必须可审计、可到期,别变成“永久特权”。
3.7 演进路线:从“看得见”到“控得住”,分三步走
这事最怕“一口吃成平台”,建议按闭环演进:
1) Phase 0:可观测性先行(1-2 周)
- 统一上报 client_type/sdk_version/capability
- 仪表盘:Top 版本分布、EOL 使用率、异常率按版本切分
2) Phase 1:版本目录 + 最小策略(2-4 周)
- Version Registry 上线(哪怕最初是配置文件)
- Policy Engine 支持:warn + block(安全封禁优先)
3) Phase 2:兼容层收口 + 渐进弃用(持续迭代)
- 兼容逻辑全部挂到“到期日/影响面”
- 每个季度消灭一批兼容债务(不然它会反过来消灭你)
最后一句话总结:
SDK/Client Version 治理不是“管理版本号”,而是把“识别-决策-执行-审计”变成系统能力。
4. 常见坑:你以为你在用第一性原理,其实你在“重命名偏见”
坑 1:把“约束”当“借口”
“我们时间紧,所以先不做监控。”
翻译一下:我们更愿意把问题留给未来的自己(或者值班同学)。
更靠谱的做法是:
监控不做全量,但做最小闭环:关键接口指标 + 错误日志 + 追踪采样。
别把“没有”当成“以后会有”。
坑 2:只推导成功路径
成功路径永远很美,失败路径才是你系统的真实样子。
尤其是分布式系统:超时比报错更常见,因为它会让你误以为“也许成功了”。
建议你把“失败矩阵”写进设计文档: - 下游超时 -> 重试/降级/熔断? - 重试导致放大流量 -> 限流/隔离? - 重复请求 -> 幂等键? - 部分失败 -> 补偿任务/对账?
5. 我常用的“第一性原理架构画布”(模板)
你可以直接复制到设计文档里:
【场景】谁在什么情况下用?峰值与频率?
【目标】SLO / 延迟 / 吞吐 / 成本 / 交付窗口
【不变量】合规 / 一致性 / 可用性(至少3条)
【约束】人/钱/时间/环境/组织
【推导】不变量/约束 -> 设计选择 -> 代价 -> 缓解
【边界】一致性域划分、数据归属、职责边界
【失败路径】超时/重试/降级/熔断/限流/幂等/补偿
【可观测性】日志/指标/追踪/审计/成本
【演进路线】MVP -> v2 -> v3(拆分/扩容/迁移)
【决策记录】ADR 列表(为什么这样选,未来怎么推翻)
总结
第一性原理不是“把问题想得更复杂”,恰恰相反:它是把架构从潮流里捞出来,放回需求与约束的地面上。
当你能清晰写出“不变量”和“约束”,很多争论会自动消失——因为答案已经被推导出来了。
扩展阅读
- “Architecture Decision Record (ADR)”:用可追溯的方式记录取舍(搜索关键词:
ADR template) - “Release It!”:失败模式、稳定性、隔离与熔断(一本老书,但很能打)
- “Designing Data-Intensive Applications”:一致性、复制、分区、流式系统(厚,但值)
- “Google SRE Book”:SLO/错误预算/可靠性工程方法论
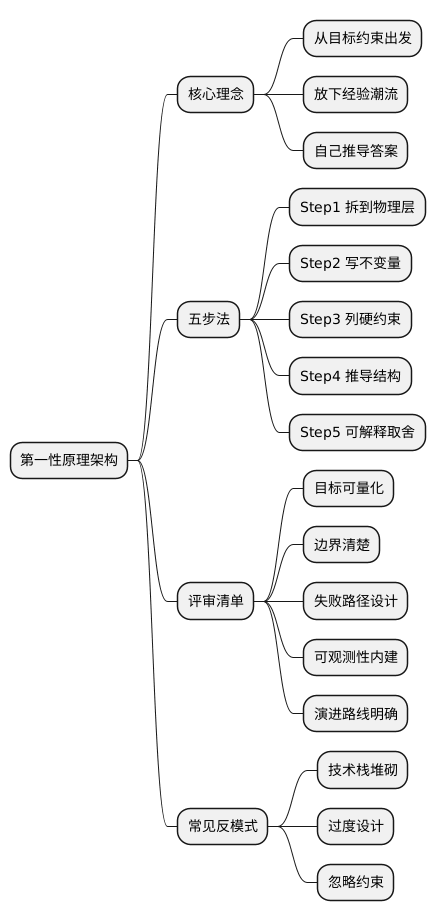
@startmindmap
* 第一性原理架构
** 核心理念
*** 从目标约束出发
*** 放下经验潮流
*** 自己推导答案
** 五步法
*** Step1 拆到物理层
*** Step2 写不变量
*** Step3 列硬约束
*** Step4 推导结构
*** Step5 可解释取舍
** 评审清单
*** 目标可量化
*** 边界清楚
*** 失败路径设计
*** 可观测性内建
*** 演进路线明确
** 常见反模式
*** 技术栈堆砌
*** 过度设计
*** 忽略约束
@endmindmap
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。