设计一个学习职场英语的 AI Agent(LLM Agent 架构 + 日常闭环 + 打分)
Posted on Mon 23 February 2026 in Tech
| Abstract | 设计一个学习职场英语的 AI Agent |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Version | v1.0 |
| Updated | 2026-02-23 |
| License | CC-BY-NC-ND 4.0 |
0. 背景(Background)
学“职场英语”真正难的地方,通常不是词汇量,而是 conversion to production:看得懂一句话,不代表你在会议里能顺口说出来。
如果把它当成一个系统问题,很多人缺的不是材料,而是闭环:
- Input 没有 Output(学了但不测)
- Output 没有 Measurement(测了但不打分、没历史)
- Measurement 没有 Scheduling(没 spaced repetition、也没有 next review time)
这篇文章做一份纯技术设计:用一个 LLM-powered learning agent,把学习固化成固定节奏的 daily loop:
- Morning:Learn(精选输入 + minimal rewrite)
- Evening:Test(在时间压力下强制输出)
- Next day:Review(只复习昨天翻车点 + 小幅增量)
参考的 agent 架构拆分来自 Lilian Weng 的文章 LLM Powered Autonomous Agents:https://lilianweng.github.io/posts/2023-06-23-agent/。
1. Agent 架构(planning / memory / tool use / reflection)
沿用 Weng 的拆法:把 LLM 当作“脑子”,外面挂四个模块:
- Planning:选今日主题,生成学习与测验任务
- Memory:持久化 sentence bank、打分、测验历史
- Tool use:dictionary、TTS/STT、计时、调度、存储
- Reflection:错误分析 → 更新分数 → 安排下一次复习
这里的“autonomy” 应该是有边界的:不要让它跑开放式任务,只让它执行一个每日确定性的工作流(daily deterministic workflow)。
2. 数据模型:带双维度打分的 sentence bank
把 phrases / sentences / templates 当成“cards”管理,是一个足够简单、也便于扩展的数据抽象。
2.1 Core entity
SentenceCard
id: string
text_en: string
meaning_zh: string
scenario_tags: [string] # e.g., status-update, scope, risk, alignment
utility: int (1..5) # 实用度(用得上/用得多不多)
mastery: int (1..5) # 熟练度(说得顺不顺)
examples: [string] # variations / rewrites
last_seen_at: datetime
next_due_at: datetime
stats:
attempts: int
correct: int
avg_latency_ms: int
last_errors: [string] # e.g., preposition, tense, word order
2.2 为什么要两套分数(实用度 / 熟练度)
把“重要性”和“熟练度”揉成一个分数,会把优先级排序搞乱。
- 实用度 (1–5) 解决:这句话值不值得学?(用不用得上)
- 熟练度 (1–5) 解决:这句话你是否已经“拥有”?(能不能顺口说出来)
一个够用的 priority 公式:
[ \text{priority} = \text{utility} \times (6 - \text{熟练度}) ]
高实用度 + 低熟练度的 card 会自然浮到最上面。
3. 调度(Scheduling):morning learn / evening test / next-day review
3.1 Daily workflow(高层流程)
- Morning Learn
- Select theme
- Pick 5 cards by priority (and due status)
-
For each card: show meaning + one “rewrite slot” (replace nouns with today’s context)
-
Evening Test
- 6 prompts max (keep it short)
- 2× zh→en (timed), 2× en→zh, 2× situational completion
-
Record correctness, latency, and error types
-
Next-day Review
- Review only failure points(熟练度最低 / 昨天做错 / 今天到期)
- Add 2 new cards only after review passes
3.2 Spaced repetition 策略(实用版本)
你不需要一上来就实现完整的 SM-2。
可以先用熟练度映射出 interval buckets:
| 熟练度 | Next interval |
|---|---|
| 1 | 1 day |
| 2 | 2 days |
| 3 | 4 days |
| 4 | 7 days |
| 5 | 14 days |
再用“failure events”覆盖调度(更贴近真实学习):
- If wrong in evening test →
next_due_at = tomorrow - If latency too high(例如 > 8s)→ treat as partial failure
4. 打分更新:把 test 结果映射到熟练度(1–5)
4.1 Signals(信号)
每个 prompt 收集三类信号即可:
- Correctness:correct / partial / wrong
- Latency:time-to-first-complete-answer
- Error type:grammar / word choice / missing nuance / register too casual
4.2 更新规则(简单且稳定)
对外暴露“熟练度”为整数,但内部维护一个浮点分值:
delta =
+1.0 if correct and latency <= 5s
+0.5 if correct and latency in (5s..8s]
+0.0 if partial
-1.0 if wrong
mastery_raw = clamp(mastery_raw + delta, 1.0, 5.0)
mastery = round_half_up(mastery_raw)
这样能避免熟练度抖得太厉害(尤其是刚开始学的阶段)。
4.3 实用度打分(1–5)
实用度通常不是“自动测出来的”,它更像一个 product decision。
两个可行做法:
- Manual:每周回顾一次,按真实使用频率升/降
- Observed(可选):用户在轻量 UI 上点一下“今天用过”,系统据此统计
5. 接口与实现草图(Python)
5.1 CLI surface(命令行接口示意)
agent learn --theme "status update" --limit 5
agent test --limit 6
agent review --limit 5
agent add --text "Let’s align on the scope first." --meaning "先对齐范围"
agent stats --top 20
5.2 Module skeleton
from dataclasses import dataclass
from datetime import datetime, timedelta
from typing import List, Optional
@dataclass
class SentenceCard:
id: str
text_en: str
meaning_zh: str
scenario_tags: List[str]
utility: int # 实用度 1..5
mastery: int # 熟练度 1..5
last_seen_at: Optional[datetime] = None
next_due_at: Optional[datetime] = None
class MemoryStore:
def load_due(self, now: datetime, limit: int) -> List[SentenceCard]:
raise NotImplementedError
def load_by_priority(self, limit: int) -> List[SentenceCard]:
raise NotImplementedError
def save_attempt(self, card_id: str, correct: bool, latency_ms: int, error_type: str) -> None:
raise NotImplementedError
def update_mastery(self, card_id: str, mastery: int, next_due_at: datetime) -> None:
raise NotImplementedError
class Scheduler:
def next_interval_days(self, mastery: int) -> int:
return {1: 1, 2: 2, 3: 4, 4: 7, 5: 14}[mastery]
def schedule_next(self, now: datetime, mastery: int, failed: bool) -> datetime:
if failed:
return now + timedelta(days=1)
return now + timedelta(days=self.next_interval_days(mastery))
5.3 Tooling hooks(工具挂钩点)
- TTS: generate audio for
text_en - STT (optional): score pronunciation; keep it local if possible
- Dictionary: fetch example usages (bounded; avoid flooding)
Security note:除非你控制 endpoint,否则不要把公司内部信息 / 项目代号 / 客户数据喂给第三方工具或外部服务。
6. 示例句子集(starter pack)
下面给一个最小的 “workplace core” 集合(你肯定要按自己工作场景裁剪):
| # | Sentence | Tag | 实用度 | 熟练度 |
|---|---|---|---|---|
| 1 | Let’s align on the scope first. | alignment | 5 | 2 |
| 2 | Here’s the latest status update. | status | 5 | 3 |
| 3 | The risk is that we might slip the timeline. | risk | 5 | 2 |
| 4 | Can we clarify the acceptance criteria? | requirement | 5 | 2 |
| 5 | I’m blocked by X. | blocker | 5 | 3 |
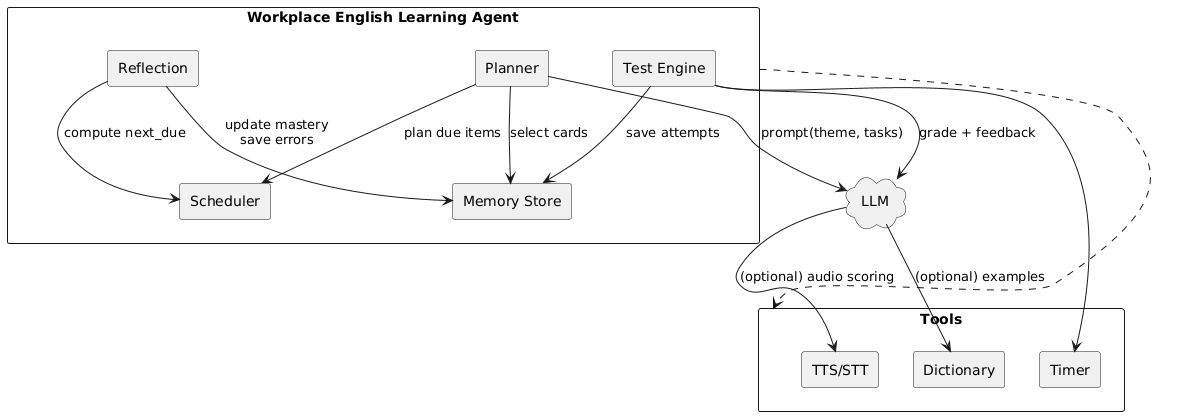
7. 架构图(Diagram)
@startuml
skinparam backgroundColor #FFFFFF
skinparam componentStyle rectangle
rectangle "Workplace English Learning Agent" as Agent {
[Planner] as Planner
[Memory Store] as Memory
[Scheduler] as Scheduler
[Test Engine] as Test
[Reflection] as Reflect
}
cloud "LLM" as LLM
rectangle "Tools" as Tools {
[Dictionary] as Dict
[TTS/STT] as Speech
[Timer] as Timer
}
Planner --> LLM : prompt(theme, tasks)
Planner --> Memory : select cards
Planner --> Scheduler : plan due items
Test --> Timer
Test --> Memory : save attempts
Test --> LLM : grade + feedback
Reflect --> Memory : update 熟练度\nsave errors
Reflect --> Scheduler : compute next_due
LLM --> Dict : (optional) examples
LLM --> Speech : (optional) audio scoring
Agent ..> Tools
@enduml
References
- Lilian Weng, LLM Powered Autonomous Agents:
https://lilianweng.github.io/posts/2023-06-23-agent/ - Spaced repetition:
https://en.wikipedia.org/wiki/Spaced_repetition
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。