服务稳定性之 LMAT 和 USED:别等着报警, 先学会"看病历"
Posted on Fri 06 March 2026 in Journal • 2 min read
| Abstract | 服务稳定性之 LMAT 和 USED:别等着报警, 先学会"看病历" |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Version | v1.0 |
| Updated | 2026-03-06 |
| License | CC-BY-NC-ND 4.0 |
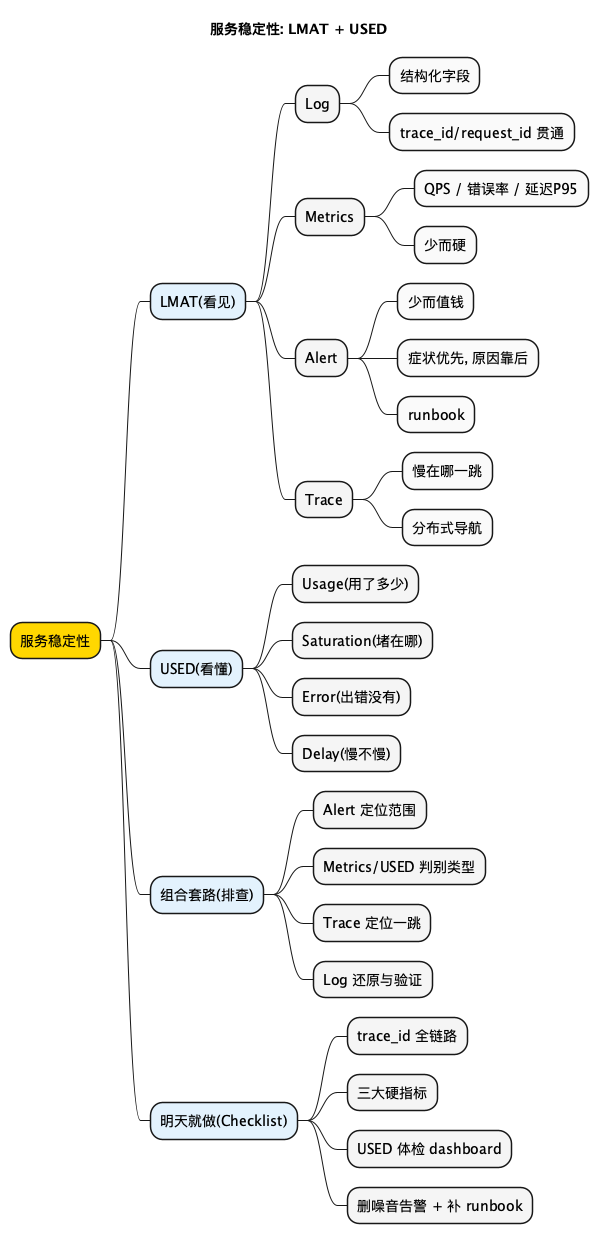
简短大纲
- 先说结论: LMAT 是你的"病历系统", USED 是你的"体检四项"
- LMAT 解决"看得见": Log/Metrics/Alert/Trace 各管一摊, 缺一个就瞎
- USED 解决"看得懂": Usage/Saturation/Error/Delay 一眼看出系统是"累了"还是"病了"
- 怎么落地: 指标先行、告警做减法、链路追踪当导航、日志别当垃圾桶
- 收尾: 一份可以照抄的排查/建设 checklist + 思维导图
服务稳定性之 LMAT 和 USED
隐患险于明火, 防范胜于救灾, 责任重于泰山。
这句话放在稳定性领域, 翻译成人话就是: 别等着报警响了才想起来"要不要做观测"。
我见过不少团队的稳定性建设, 走的都是同一条歪路:
- 线上一炸, 先开会
- 会上先问"有没有日志"
- 找到日志之后发现: 不是没打, 是打得太多, 像垃圾桶
- 再问"有没有指标"
- 指标倒是有, 但没有告警, 或者告警像鞭炮, 一响一片
最后大家在群里拼图: 你贴一段日志, 我贴一张截图, 他贴一条 Trace 链路。像不像在 ICU 门口拼病历?
所以这篇我只讲两件事:
- LMAT: Log, Metrics, Alert, Trace。观测的四件套, 你得先把"病历系统"搭起来。
- USED: Usage, Saturation, Error, Delay。体检的四项指标, 你得学会"看懂指标"。
一个负责"看见", 一个负责"看懂"。别再靠直觉救火了。
1. LMAT: 观测四件套, 少一个都别说自己"可观测"
LMAT 不是新概念, 但它特别适合当团队的共同语言。因为它把"观测"拆成四个明确的盒子, 每个盒子都有边界。
1.1 Log: 记事实, 不要写作文
日志的价值是"还原现场", 不是"情绪宣泄"。
- 你想要的是: 请求是谁、干了什么、在哪一步失败、花了多久
- 你不想要的是: 一堆重复堆栈 + 一堆"发生异常" + 一堆无关上下文
最实用的建议只有两条:
- 结构化: 关键字段固定下来, 用 JSON 或 key=value (request_id, user_id, trace_id, latency_ms, error_code)
- 能串起来: 日志里一定要有
trace_id/request_id, 不然你永远在"翻垃圾堆"
1.2 Metrics: 先选少量"硬指标", 别贪多
指标是用来"看趋势"和"做告警"的, 它的天然优势是可聚合、可对比、可统计。
小白常见误区是: 什么都采, 结果什么都看不懂。
我的建议是从三类开始:
- 流量: QPS/吞吐
- 错误: error rate (按错误码分组更好)
- 延迟: P50/P95/P99
这三类够你把 80% 的事故先定位到"是不是这条链路"。
1.3 Alert: 告警不是越多越好, 是越少越值钱
告警是"打断你"的工具。它的成本非常高: 一响, 你就得停下手里的事。
所以告警设计的第一原则是: 宁可少, 也别吵。
几个实操建议:
- 区分症状和原因: CPU 高是原因, 用户错误率高是症状。告警优先盯症状。
- 加抖动与窗口: 少一点"毛刺报警", 多一点"趋势报警"。
- 写清 runbook: 告警里至少要告诉值班同学"下一步看哪张图、执行哪个命令"。
1.4 Trace: 这是你排查分布式系统的"导航"
Trace 的意义不是好看, 是帮你回答这句最要命的问题:
慢, 到底慢在哪一跳?
在微服务里, 你只看日志, 会像在城市里找人但没地图; 你只看指标, 会像看到交通拥堵但不知道哪条路堵。
Trace 把调用链画出来, 你就能一眼看出:
- 是网关慢, 还是下游依赖慢
- 是某个接口慢, 还是某个数据库查询慢
- 是某个租户拖垮全局, 还是普遍性退化
2. USED: 体检四项, 专治"你看见了但看不懂"
LMAT 解决的是"有工具、有数据"。但很多团队真正的痛点是:
图都有了, 还是不知道系统到底哪里不对劲。
USED 就像给你一张体检报告, 四项一看, 你大概就知道是"太累"还是"生病"。
2.1 Usage: 用了多少
Usage 是资源使用率。CPU、内存、磁盘、网络都算。
它告诉你: 你是不是把机器用满了。
2.2 Saturation: 堵在哪
Saturation 是"资源有没有排队/拥塞"。这是很多人只盯 CPU 而忽略的部分。
例子:
- CPU 不高, 但线程池排队很长
- 内存不满, 但 GC 时间拉长
- 网络带宽没打满, 但连接数/FD 用尽
一句话: Usage 是油表, Saturation 是堵车。油不一定没了, 但你已经堵死了。
2.3 Error: 出错没有
Error 不只指 5xx, 也包括:
- 超时 (timeout)
- 降级/熔断 (fallback/circuit open)
- 重试风暴(retry storm)导致的"看似成功, 实则抖动"
如果 Error 上去了, 你基本不用纠结: 这是事故。
2.4 Delay: 慢不慢
Delay 更像用户体感。它可以落在:
- 端到端延迟(用户点击到返回)
- 服务端延迟(P95/P99)
- 依赖延迟(DB/Cache/第三方 API)
Delay 和 Saturation 常常是一起出现的: 先排队, 再变慢。
3. 把 LMAT 和 USED 配起来, 你就有了一套"排查套路"
我给你一个简单但挺管用的顺序:
- Alert 先告诉你哪里疼: 哪个服务、哪个接口、哪个区域
- Metrics/USED 告诉你像什么病: 是 Usage 上去了, 还是 Saturation 堵了, 还是 Error/Delay 飙了
- Trace 带你定位到具体一跳: 慢在网关? 慢在 DB? 慢在下游某个调用?
- Log 还原现场并确认修复: 错误码、参数、异常栈、边界条件, 以及修复后是否回归
这就是为什么我说: LMAT 是病历系统, USED 是体检四项。
缺了 LMAT, 你连数据都没有; 缺了 USED, 你看着数据发呆。
4. 明天就能做的 7 件事(Checklist)
- [ ] 给所有服务补齐 trace_id: log 和 trace 先能串起来
- [ ] 把最重要的 3 个指标立起来: QPS / error rate / latency(P95)
- [ ] 用 USED 重新审视一张 dashboard: 每个服务至少能回答 Usage/Saturation/Error/Delay
- [ ] 删掉 30% 的噪音告警: 没有行动指引的, 先关掉
- [ ] 每个告警补一条 runbook: 下一步看哪张图, 执行什么命令
- [ ] 挑一个"最慢接口"做 Trace 深挖: 找出最慢一跳并修一次
- [ ] 把一句口号落地成规则: "症状告警优先, 原因告警靠后"
扩展阅读
- Google SRE Book — 稳定性方法论的经典
- OpenTelemetry Documentation — Trace/Metric/Log 的一体化标准
- Prometheus Alerting — 告警体系的基本功
思维导图
@startmindmap
<style>
mindmapDiagram {
node { BackgroundColor #FAFAFA }
:depth(0) { BackgroundColor #FFD700 }
:depth(1) { BackgroundColor #E3F2FD }
:depth(2) { BackgroundColor #F5F5F5 }
}
</style>
title 服务稳定性: LMAT + USED
* 服务稳定性
** LMAT(看见)
*** Log
**** 结构化字段
**** trace_id/request_id 贯通
*** Metrics
**** QPS / 错误率 / 延迟P95
**** 少而硬
*** Alert
**** 少而值钱
**** 症状优先, 原因靠后
**** runbook
*** Trace
**** 慢在哪一跳
**** 分布式导航
** USED(看懂)
*** Usage(用了多少)
*** Saturation(堵在哪)
*** Error(出错没有)
*** Delay(慢不慢)
** 组合套路(排查)
*** Alert 定位范围
*** Metrics/USED 判别类型
*** Trace 定位一跳
*** Log 还原与验证
** 明天就做(Checklist)
*** trace_id 全链路
*** 三大硬指标
*** USED 体检 dashboard
*** 删噪音告警 + 补 runbook
@endmindmap
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。